parsnip model object
Call:
stats::lm(formula = flipper_length_mm ~ body_mass_g, data = data)
Coefficients:
(Intercept) body_mass_g
136.72956 0.01528 W#07: Fitting Linear Models, Interaction Effects, Nonlinear Models, Predicting Categorical Variables
Recap: Linear model
Flipper length as a function of body mass.
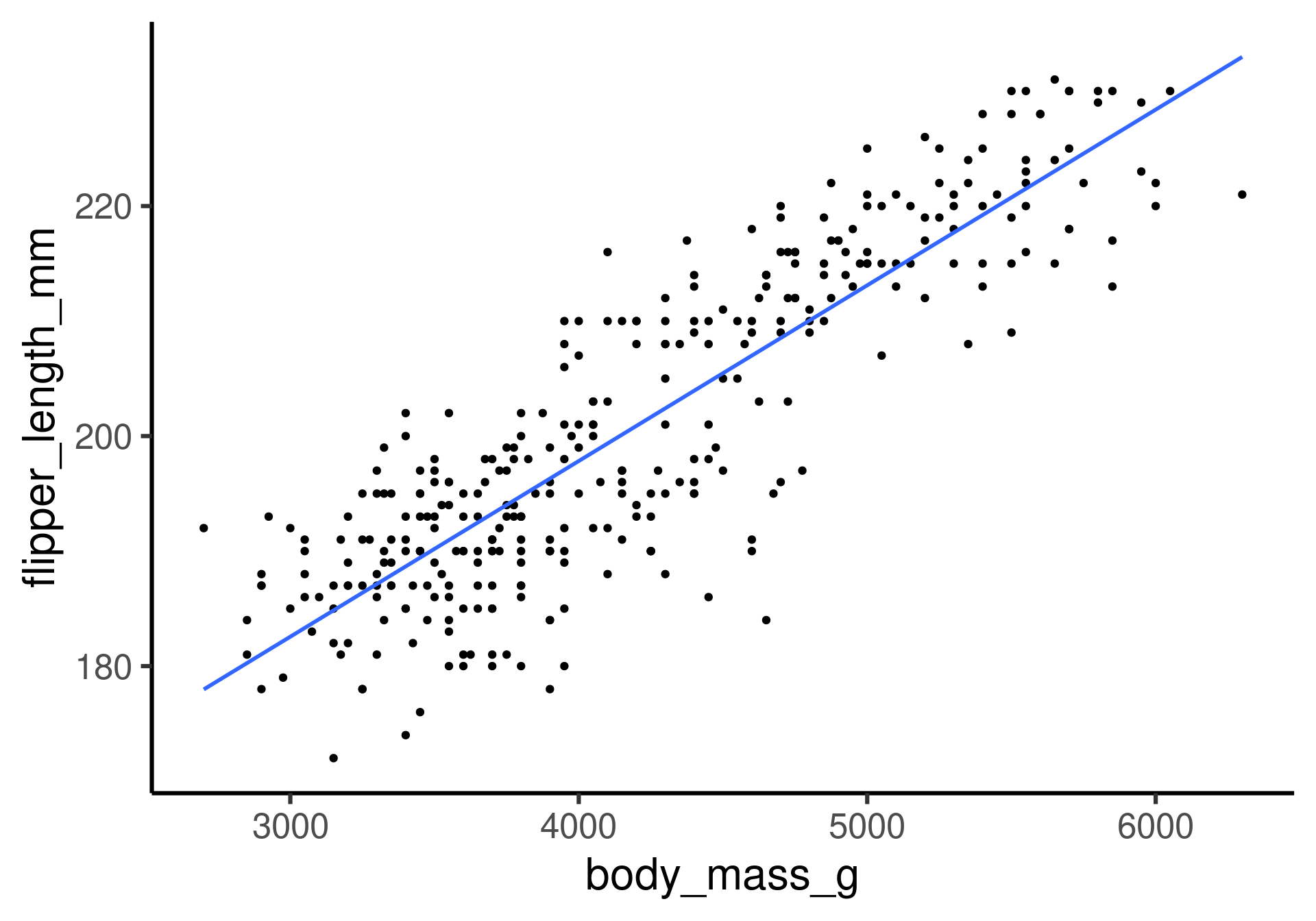
The fitting question: How can we get this line?
Recap: A line
A line is a shift-scale transformation of the identity function usually written in the form
\[f(x) = a\cdot x + b\]
where \(a\) is the slope, \(b\) is the intercept.

Visualization of residuals
The residuals are the gray lines between predictid values on the regression line and the actual values.

Proporties of least squares regression
The regression lines goes through the point (mean(x), mean(y)).
[1] 4201.754[1] 200.9152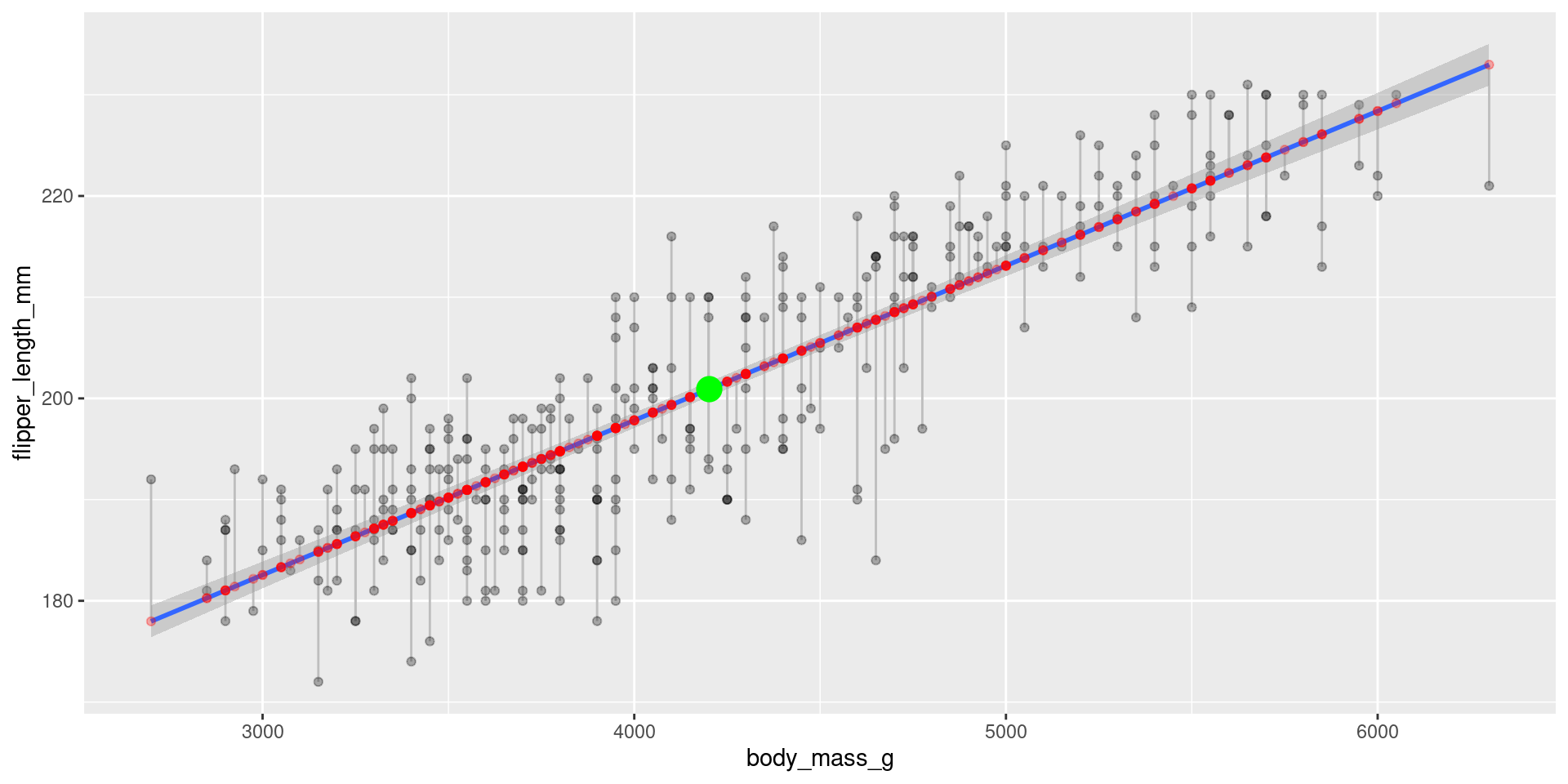
Compare to a visualization
# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 190. 0.540 351. 0
2 speciesChinstrap 5.87 0.970 6.05 3.79e- 9
3 speciesGentoo 27.2 0.807 33.8 1.84e-110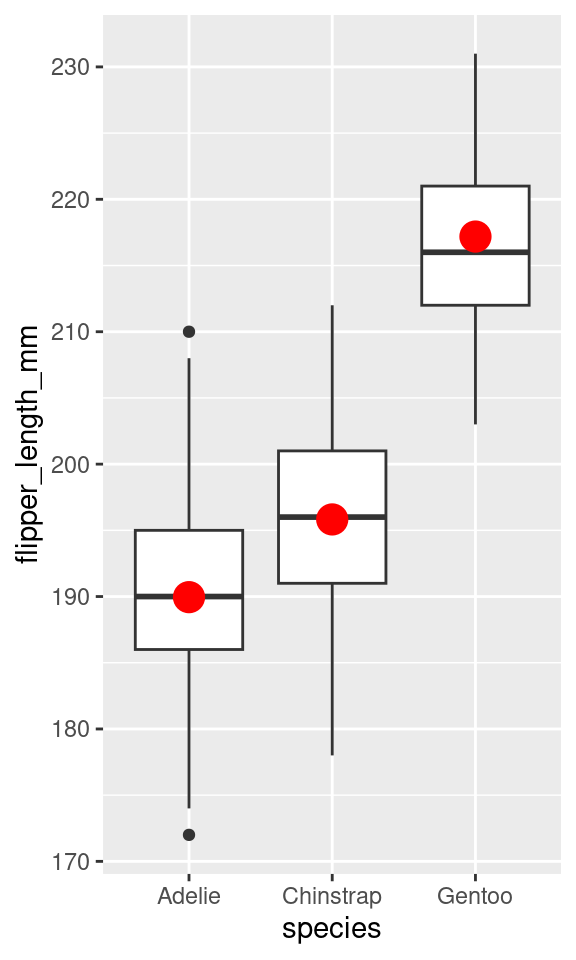
The red dots are the average values for species.
R-squared of a fitted model
\(R^2\) is the percentage of variability in the response explained by the regression model.
R-squared is also called coefficient of determination.
Definition:
\(R^2 = 1 - \frac{SS_\text{res}}{SS_\text{tot}}\)
where \(SS_\text{res} = \sum_i(y_i - f_i)^2 = \sum_i e_i^2\) is the sum of the squared residuals, and
\(SS_\text{tot} = \sum_i(y_i - \bar y)^2\) the total sum of squares which is proportional to the variance of \(y\). (\(\bar y\) is the mean of \(y\).)

Regression lines by species
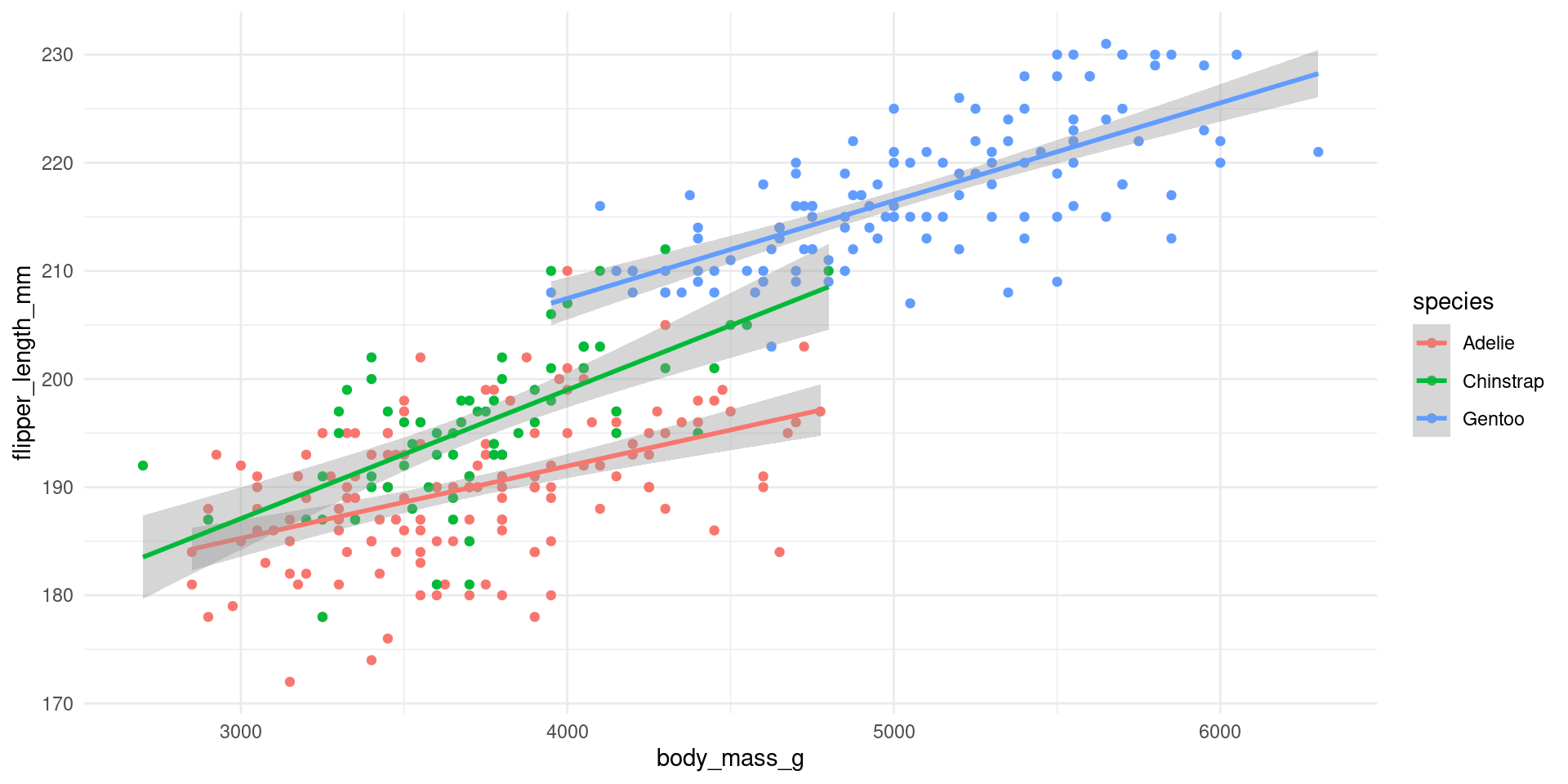
Compare the slopes to the regression output on the slides before!
When a linear model is bad
Example: Total corona cases in Germany in the first wave 2020.

\(\log\) transformation
Instead of Cumulative_cases we look at \(\log(\)Cumulative_cases\()\)
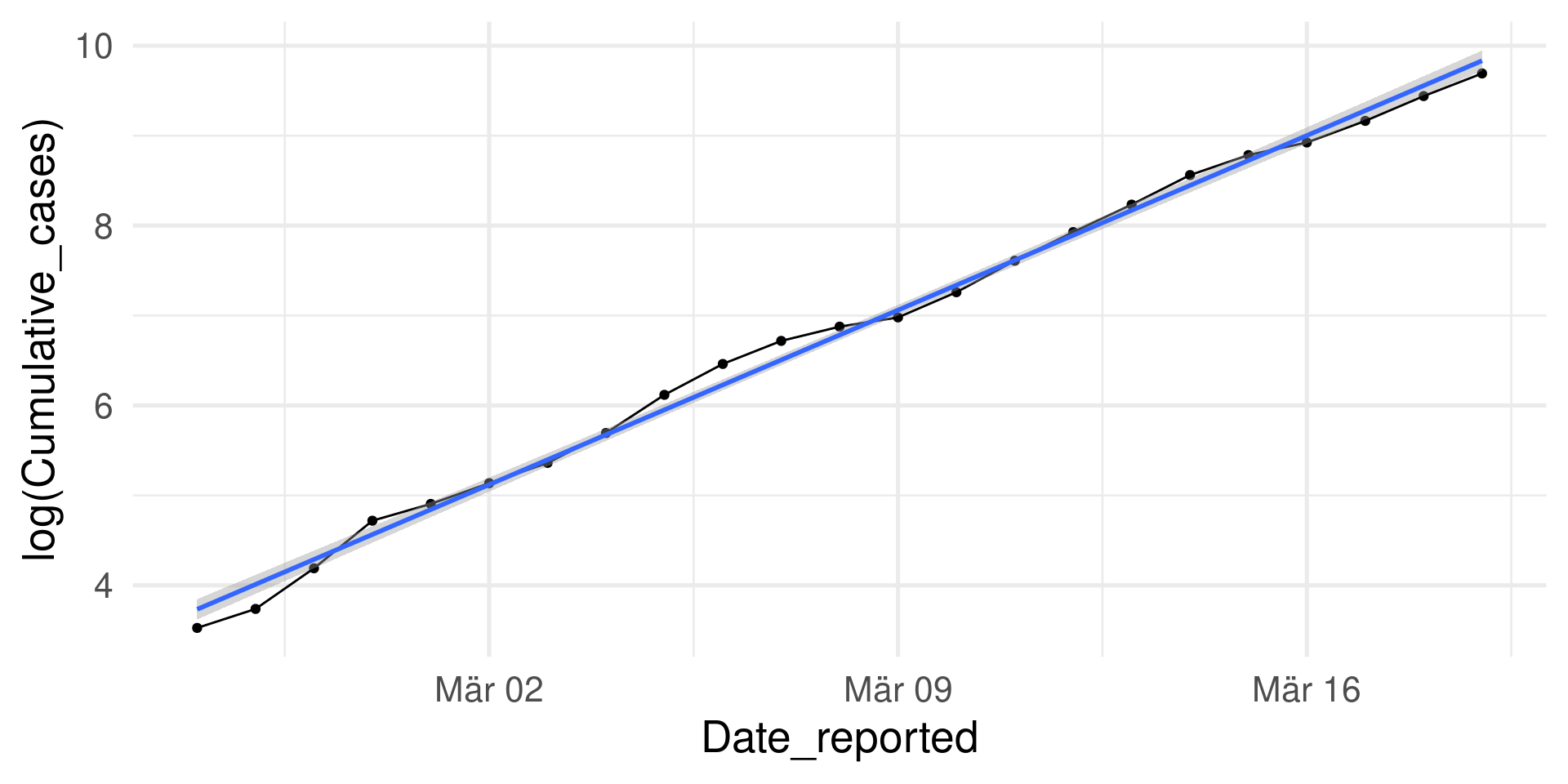
Almost perfect fit of the linear model: \(\log(y)=\log(\beta_0) + \beta_1\cdot x\)
(\(y=\) Cumulative cases, \(x=\) Days)
Exponentiation gives the model: \(y=\beta_0 e^{\beta_1\cdot x}\) (Check \(e^{\log(\beta_0) + \beta_1\cdot x} = e^{\log(\beta_0)} e^{\beta_1\cdot x} = \beta_0 e^{\beta_1\cdot x}\))
Exponential growth!
\(y=\beta_0 e^{\beta_1\cdot x}\)
For comparison: Logistic function \(y = \frac{N \beta_0 e^{\beta_1\cdot x}}{N + \beta_0 e^{\beta_1\cdot x}}\) for \(N=200000\)
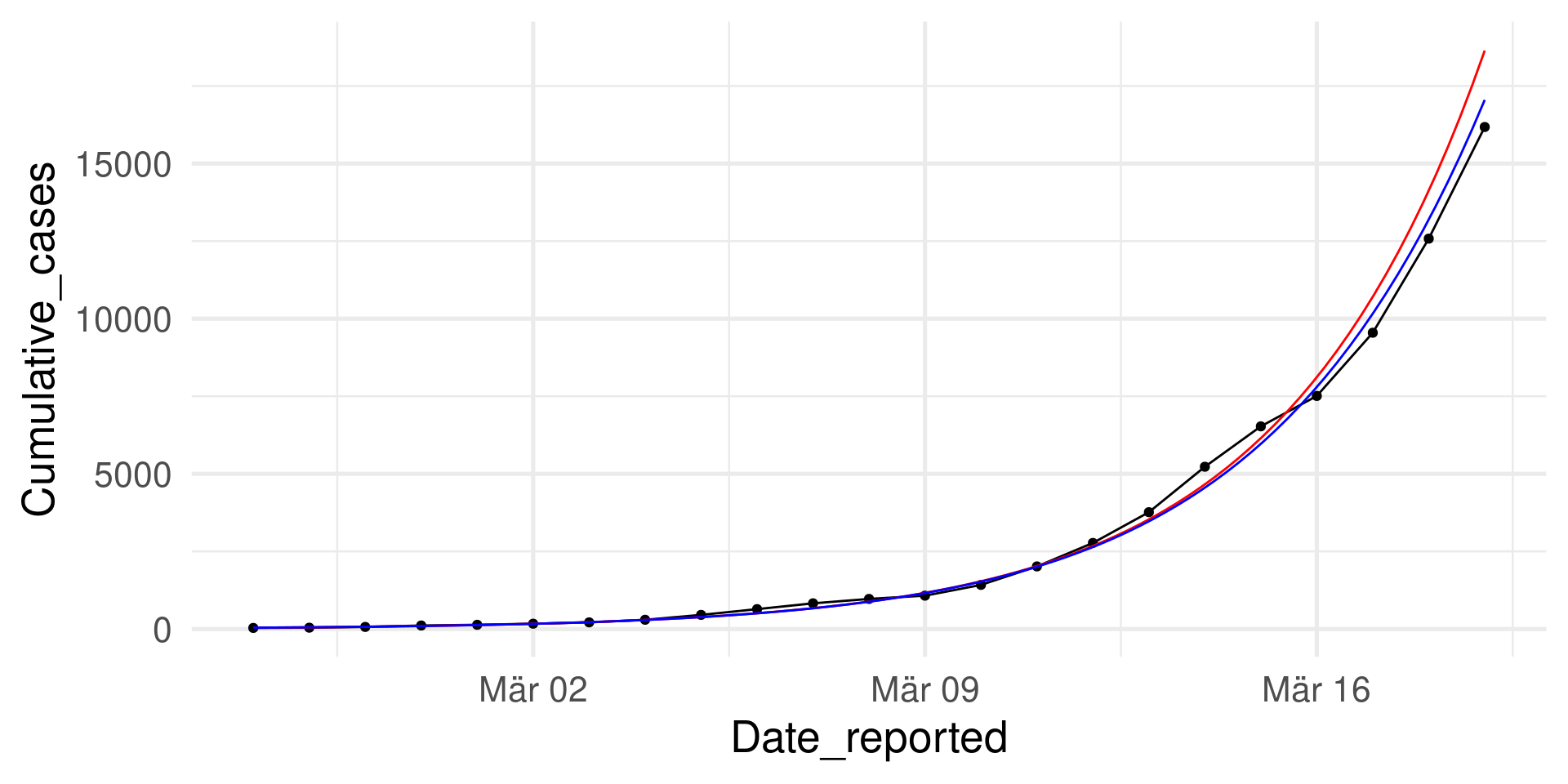
Logistic growth (as in the SI model) mimicks exponential growth initially.
\(\log\) transformation

What is the difference to the penguin model?
- \(x\) has an ordered structure and no duplicates
The fit looks so good. Why?
Because there is a mechanistic explanation behind: The SI model.
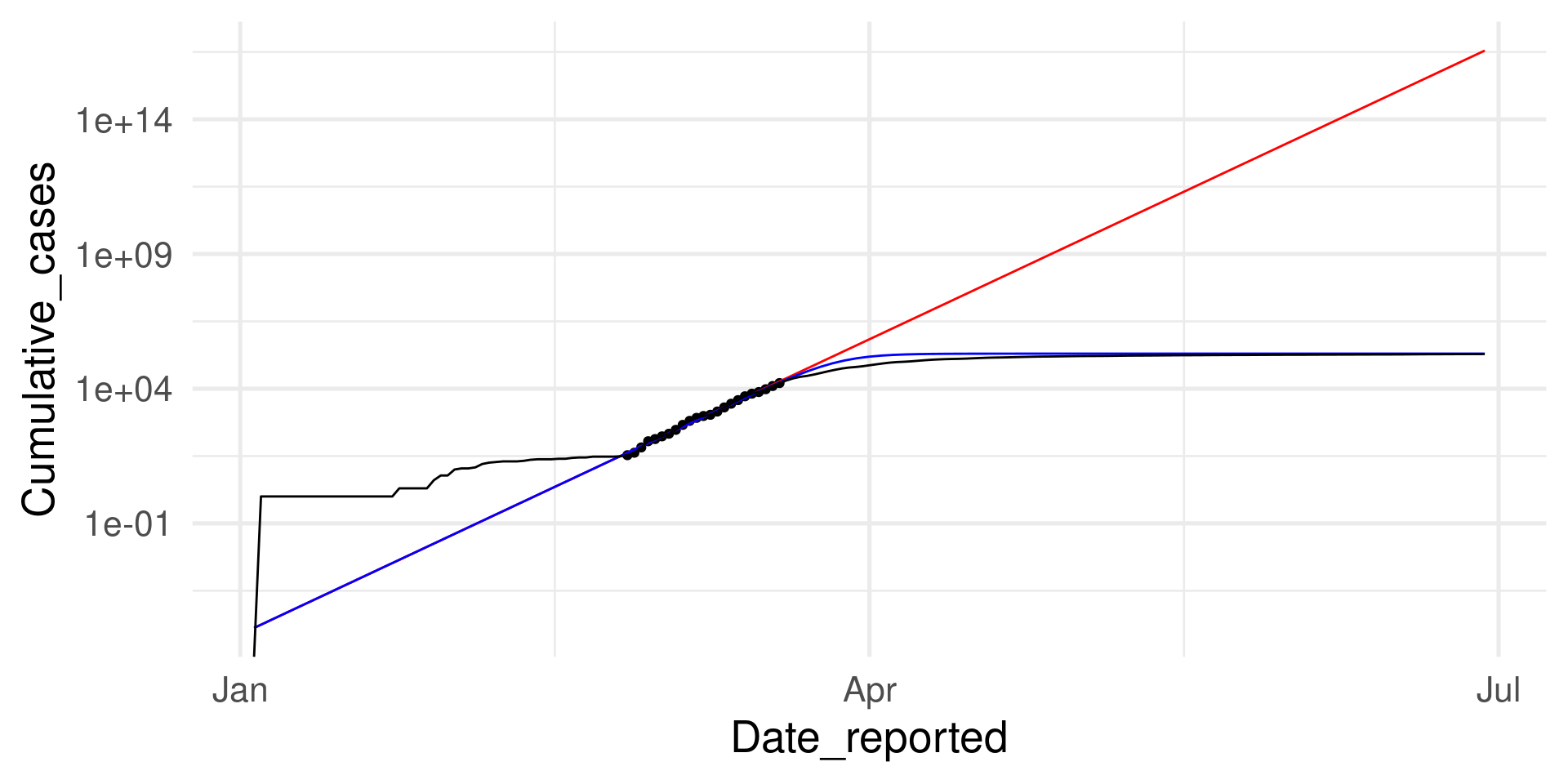
However, it works only in a certain range

However, it works only in a certain range (log scale on y)
Data exploration
Would you expect spam to be longer or shorter?

Would you expect spam subject to start with “Re:” or the like?

Linear models?
Both seem to give some signal. How can we model the relationship?
We focus first on just num_char:

parsnip model object
Call:
stats::lm(formula = as.numeric(spam) - 1 ~ num_char, data = data)
Coefficients:
(Intercept) num_char
0.118214 -0.002299 We would like to have a better concept!
A penguins example

It does not make much sense to predict 0-1-values with a linear model.
Characterising GLMs
- Generalized linear models (GLMs) are a way of addressing many problems in regression
- Logistic regression is one example
All GLMs have the following three characteristics:
- A probability distribution as a generative model for the outcome variable \(y_i \sim \text{Distribution}(\text{parameter})\)
- A linear model \(\eta = \beta_0 + \beta_1 X_1 + \cdots + \beta_k X_k\)
where \(\eta\) is related to a mean parameter of the distribution by the …
- Link function that relates the linear model to the parameter of the outcome distribution.
