
W#05: Summary Statistics, Exploratory Data Analysis, Principal Component Analysis
Data Sets 1a and 1b: Widsom of Crowd
1a: Ox weigh guessing competition 1907 (collected by Galton)
1b: Viertelfest “guess the number of sold lots”-competition 2009

Data Set 2: Palmer Penguins
Chinstrap, Gentoo, and Adélie Penguins



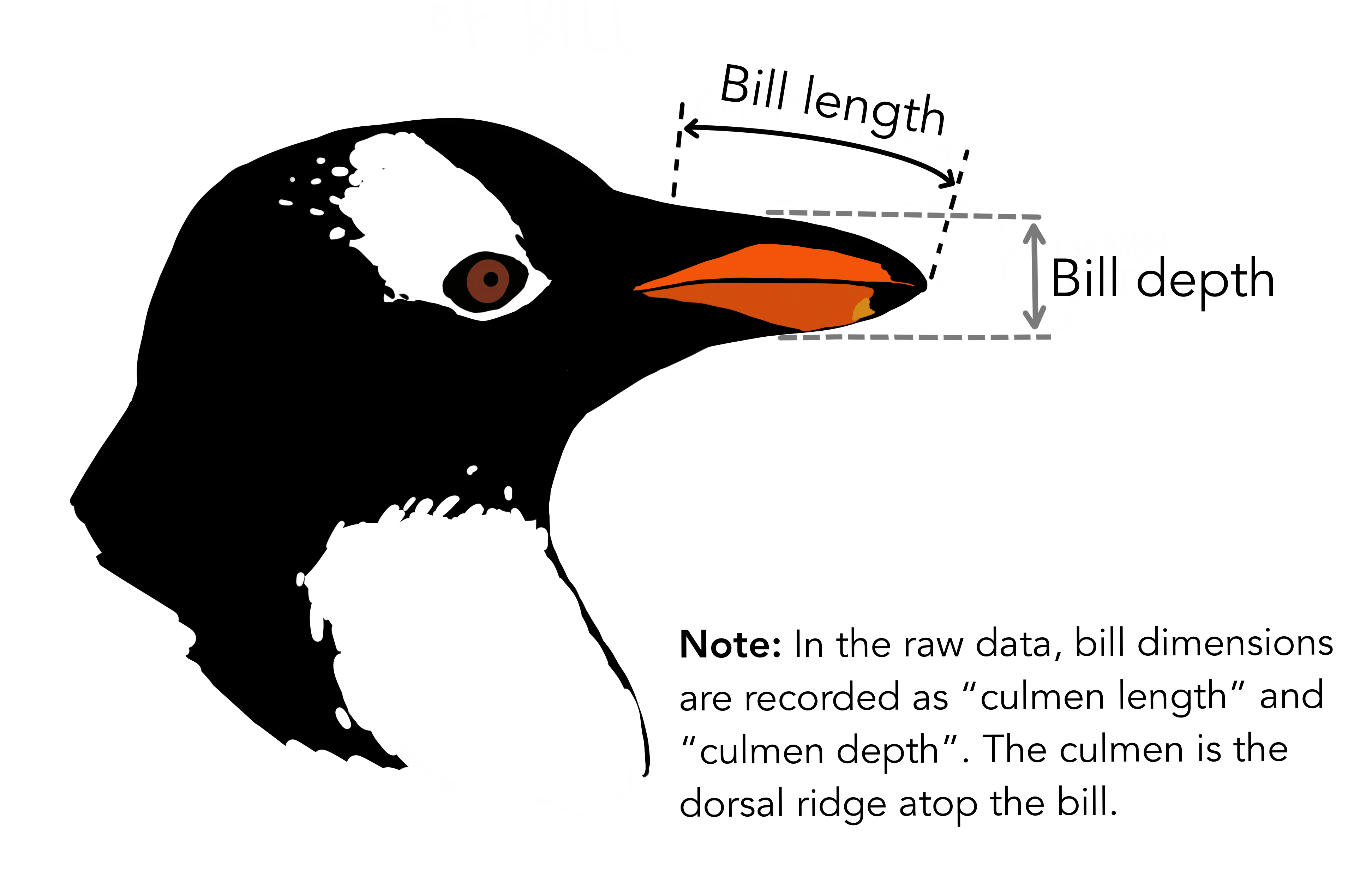
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>1a Galton: Quartiles
0% 25% 50% 75% 100%
896.0 1162.5 1208.0 1236.0 1516.0 Interpretation: What does the value at 25% mean?
The 25% of all values are lower than the value. 75% are larger.

1a Galton: 20-quantiles
0% 5% 10% 15% 20% 25% 30% 35% 40% 45% 50%
896.0 1078.3 1109.0 1126.9 1150.0 1162.5 1174.0 1181.0 1189.0 1199.0 1208.0
55% 60% 65% 70% 75% 80% 85% 90% 95% 100%
1214.0 1219.0 1225.0 1231.0 1236.0 1243.8 1255.1 1270.0 1293.0 1516.0 
1b Viertelfest: Quartiles
0% 25% 50% 75% 100%
120 5000 9843 20000 29530000 
1b Viertelfest: 20-quantiles
0% 5% 10% 15% 20% 25%
120.00 1213.25 2000.00 3115.00 4012.00 5000.00
30% 35% 40% 45% 50% 55%
5853.50 7000.00 7821.00 8705.25 9843.00 10967.50
60% 65% 70% 75% 80% 85%
12374.00 14444.00 16186.00 20000.00 27500.00 38000.00
90% 95% 100%
63649.50 99773.50 29530000.00 
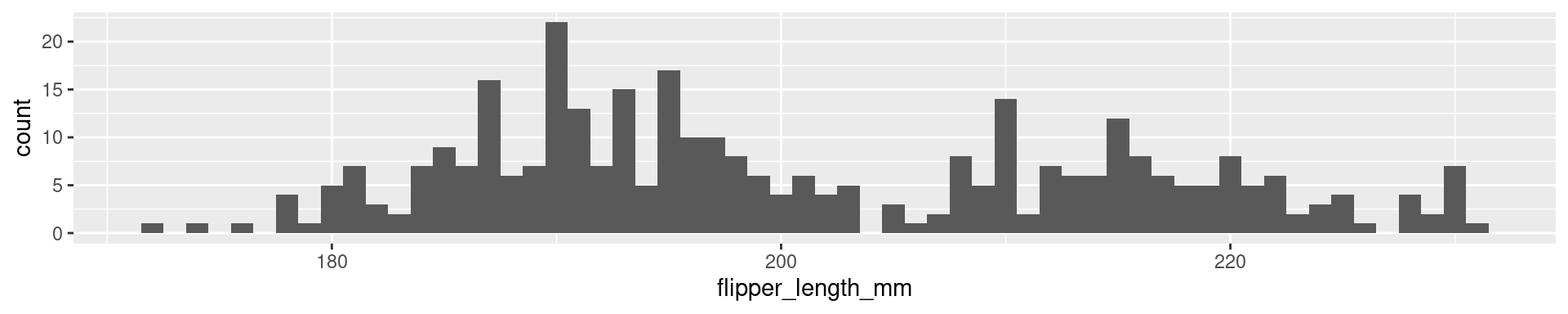
2 Palmer Penguins Flipper Length: Quartiles
0% 25% 50% 75% 100%
172 190 197 213 231 
2 Palmer Penguins Flipper Length: 20-quantiles
0% 5% 10% 15% 20% 25% 30% 35% 40% 45% 50% 55% 60%
172.0 181.0 185.0 187.0 188.0 190.0 191.0 193.0 194.0 195.0 197.0 199.0 203.0
65% 70% 75% 80% 85% 90% 95% 100%
208.0 210.0 213.0 215.0 218.0 220.9 225.0 231.0 
Interquartile range (IQR)
The difference between the 1st and the 3rd quartile. Alternative dispersion measure.
The range in which the middle 50% of the values are located.
Examples:
[1] 73.5[1] 73.58677[1] 15000[1] 848395.5[1] 23[1] 14.06171


Boxplots
A condensed visualization of a distribution showing location, spread, skewness and outliers.

- The box shows the median in the middle and the other two quartiles as their borders.
- Whiskers: From above the upper quartile, a distance of 1.5 times the IQR is measured out and a whisker is drawn up to the largest observed data point from the dataset that falls within this distance. Similarly, for the lower quartile.
- Whiskers must end at an observed data point! (So lengths can differ.)
- All other values outside of box and whiskers are shown as points and often called outliers. (There may be none.)
Boxplots vs. histograms
- Histograms can show the shape of the distribution well, but not the summary statistics like the median.

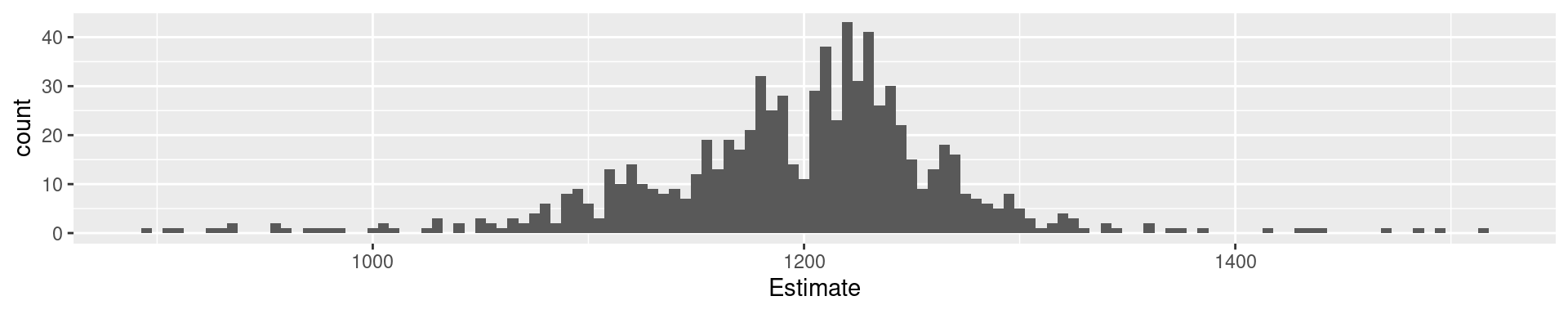
Boxplots vs. histograms
- Boxplots can not show the patterns of bimodal or multimodal distributions.

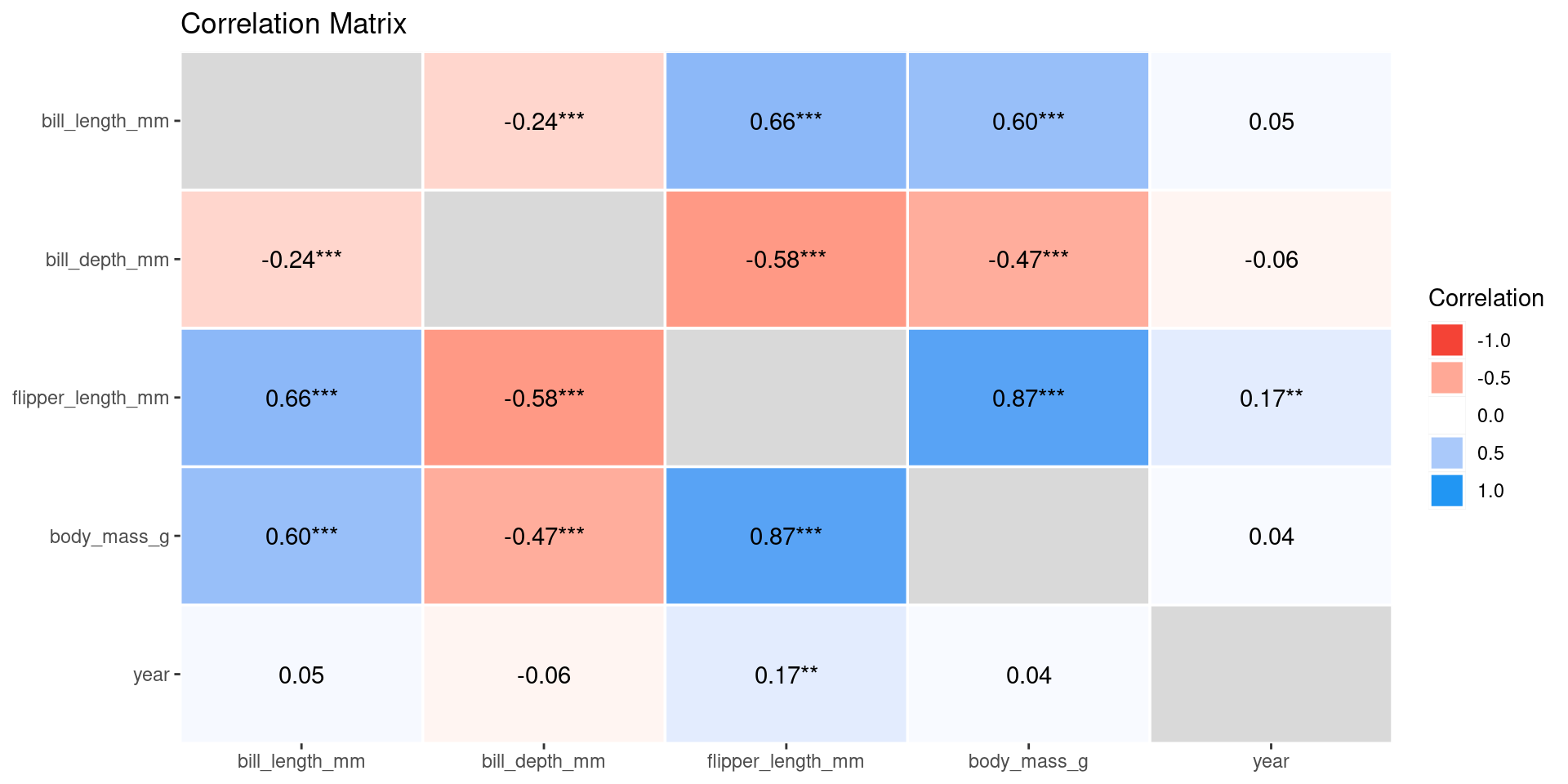
Correlation visualization
Exploratory Data Analysis
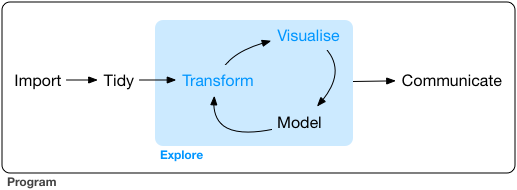
EDA is the systematic exploration of data using
- visualization
- transformation
- computation of characteristic values
- modeling
Example EDA: Strange Airports
From Homework 02:
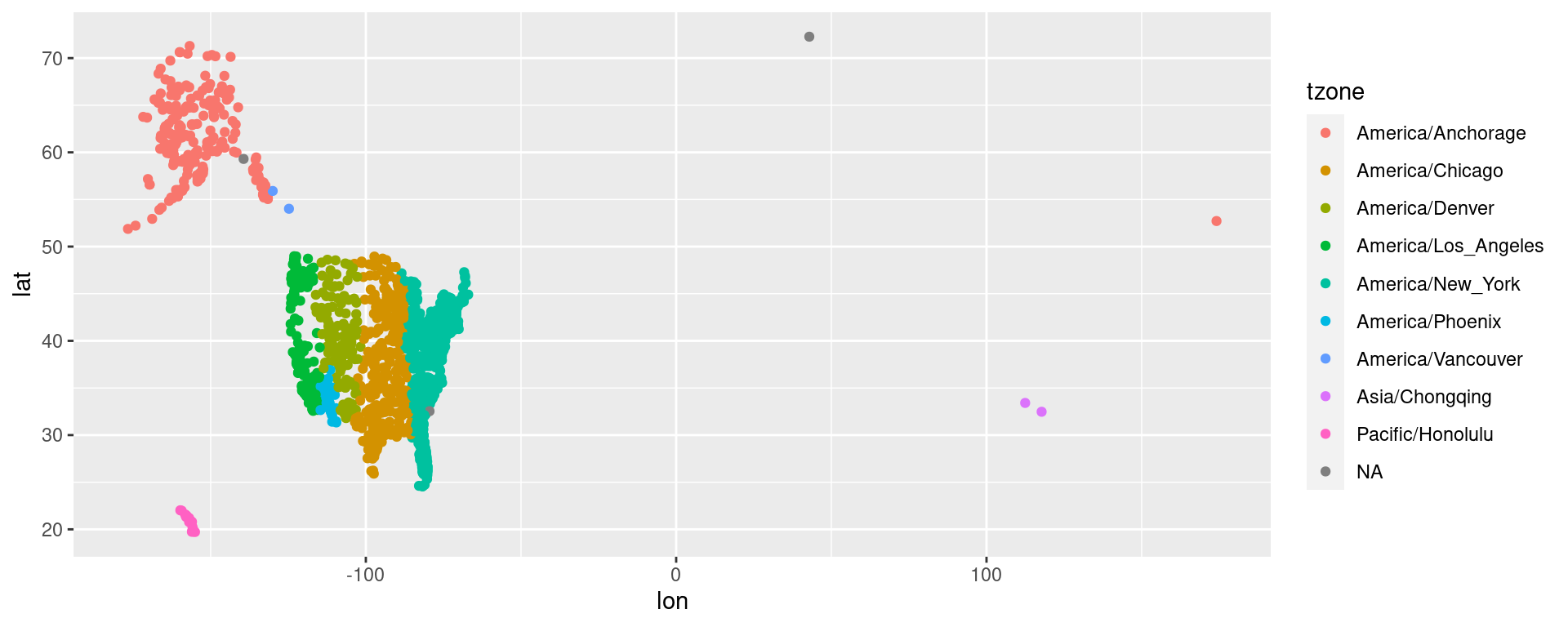
# A tibble: 4 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 DVT Deer Valley Municipal Airport 33.4 112. 1478 8 A Asia/Chongq…
2 EEN Dillant Hopkins Airport 72.3 42.9 149 -5 A <NA>
3 MYF Montgomery Field 32.5 118. 17 8 A Asia/Chongq…
4 SYA Eareckson As 52.7 174. 98 -9 A America/Anc…Airport errors
# A tibble: 4 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 DVT Deer Valley Municipal Airport 33.4 112. 1478 8 A Asia/Chongq…
2 EEN Dillant Hopkins Airport 72.3 42.9 149 -5 A <NA>
3 MYF Montgomery Field 32.5 118. 17 8 A Asia/Chongq…
4 SYA Eareckson As 52.7 174. 98 -9 A America/Anc…Correct locations (internet research and location of maps):
- Deer Valley Municipal Airport: Phoenix
33°41′N 112°05′W Missing minus for lon (W) - Dillant Hopkins Airport: New Hampshire
42°54′N 72°16′W lon-lat switched, minus (W) - Montgomery Field: San Diego
32°44′N 117°11″W Missing minus for lon (W) - Eareckson As: Alaska
52°42′N 174°06′E No error: Too west,it’s east!

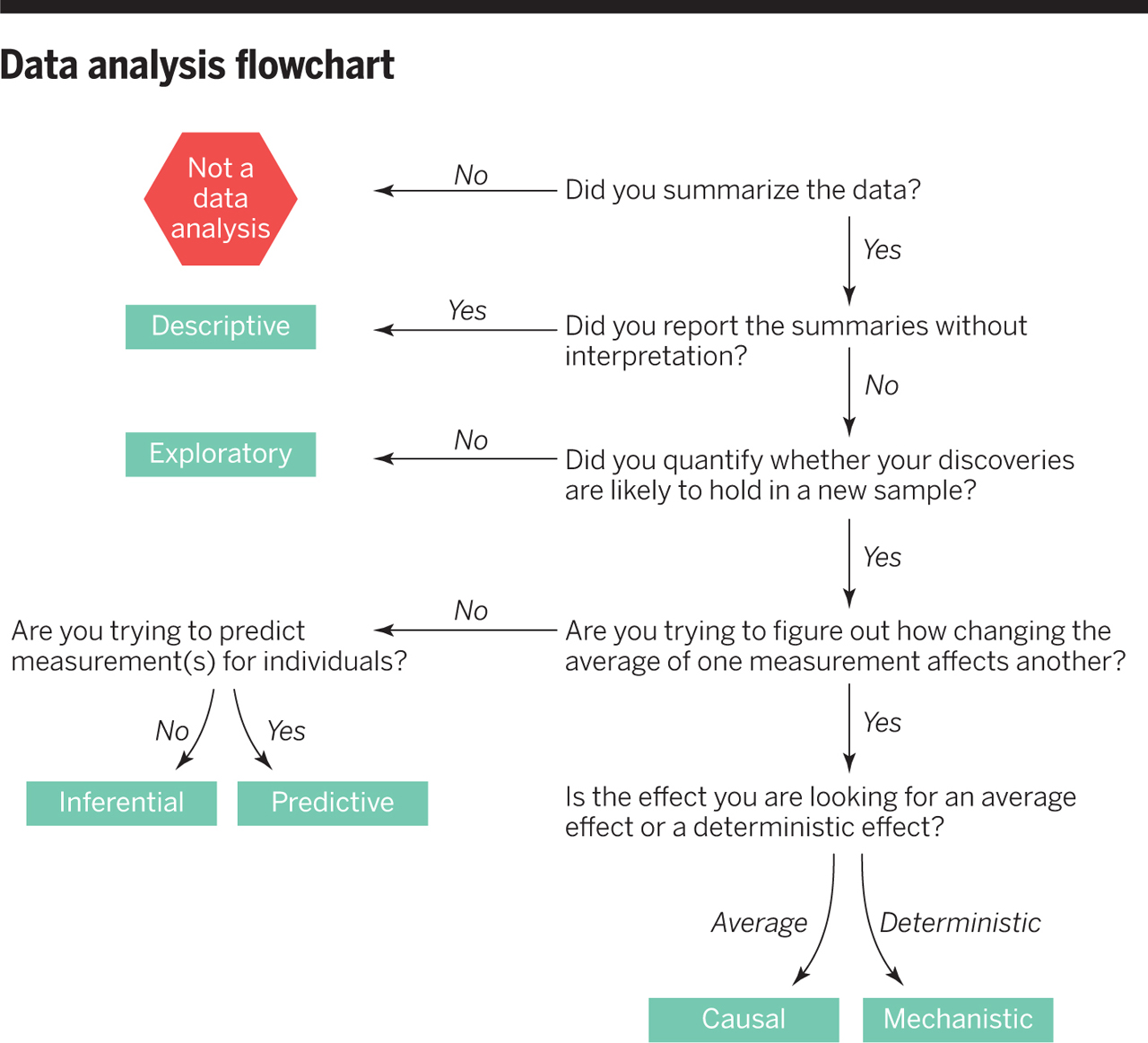
Descriptive Projects

Data Analysis Flowchart
Two Variables
Example for the new axes.
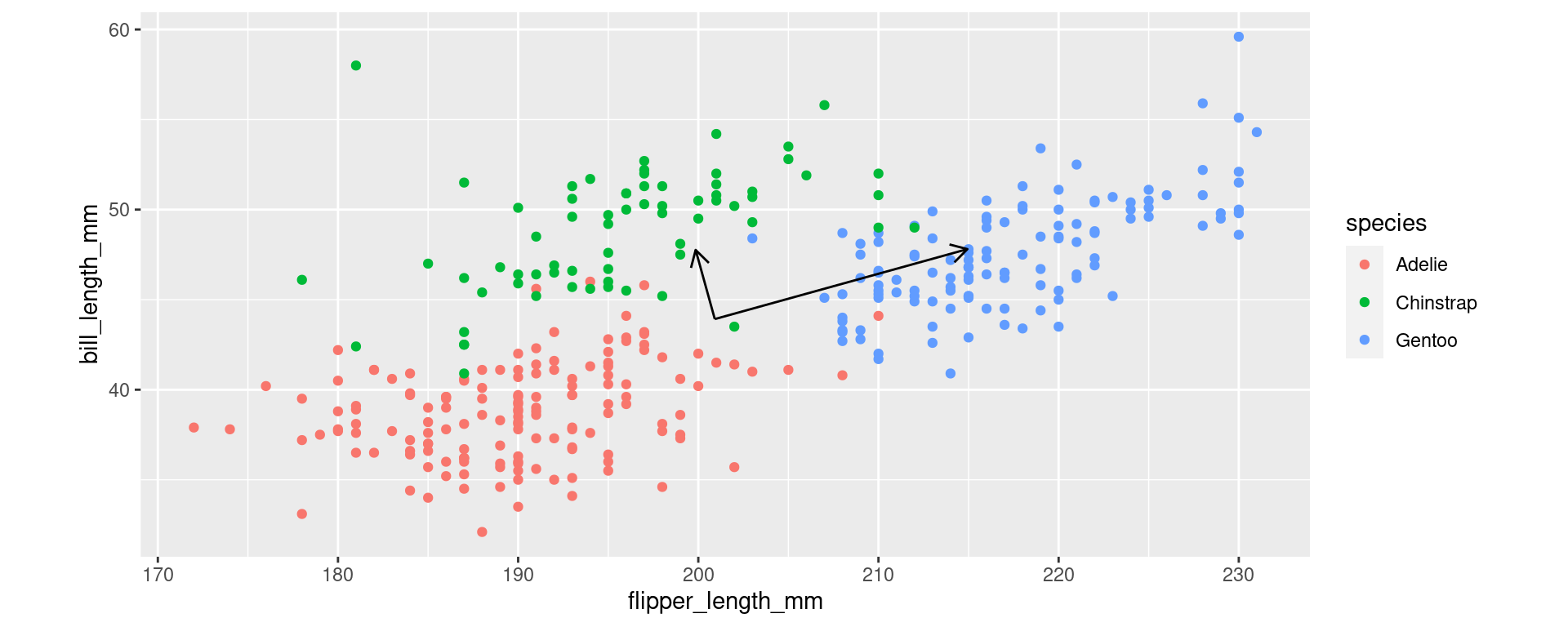
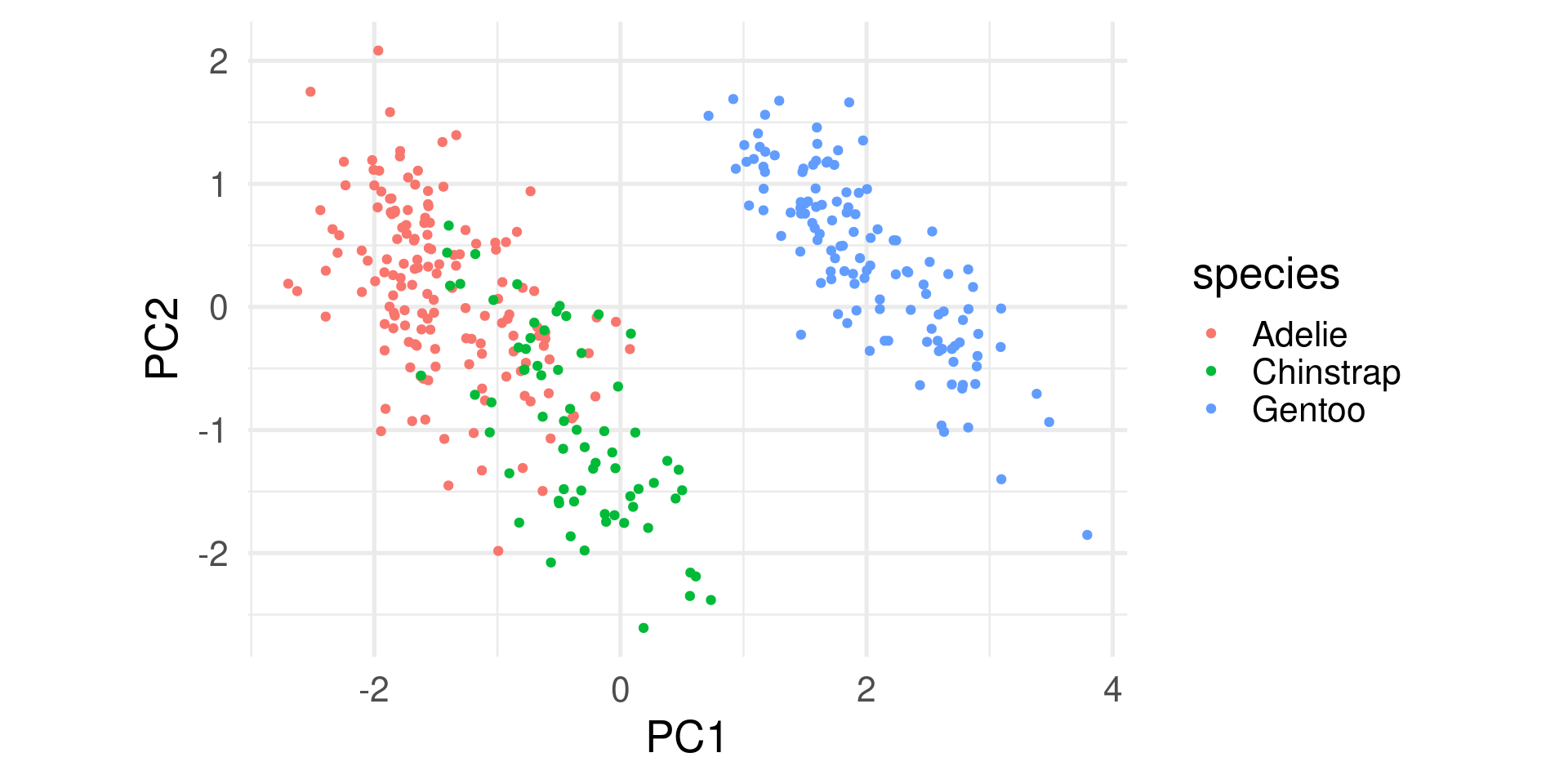
Explore data in PC coordinates
- Start plotting PC1 against PC2. By default these are the most important ones. Drill deeper later.
- Append the original data. Here used to color by species.
Variable loadings
- The columns of the rotation matrix shows how the original variables load on the principle components.
- We can try to interpret these loadings and give descriptive names to principal components.
tidyextracts the rotation matrix in long format with aPC, acolumn(for the original variable name), and avaluevariable.

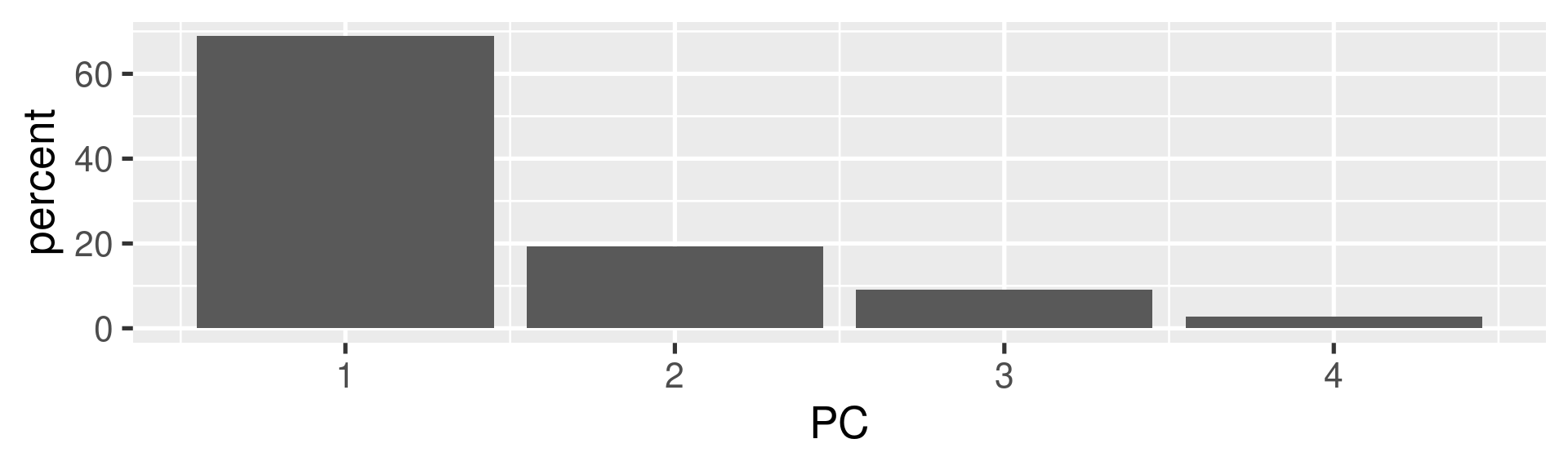
Variance explained
- Principle components are by default sorted by importance.
- The squares of the standard deviation for each component gives its variances and variances have to sum up to the sum of the variances of the original variables.
- When original variables were standardized their original variances are all each one. Consequently, the variances of the principal components sum up to the number of original variables.
- A typical plot to visualize the importance of the components is to plot the percentage of the variance explained by each component.
Interpretations (1)

- The first component explains almost 70% of the variance. So most emphasize should be on this.
- The first two explain about 88% of the total variance.
Interpretations (2)
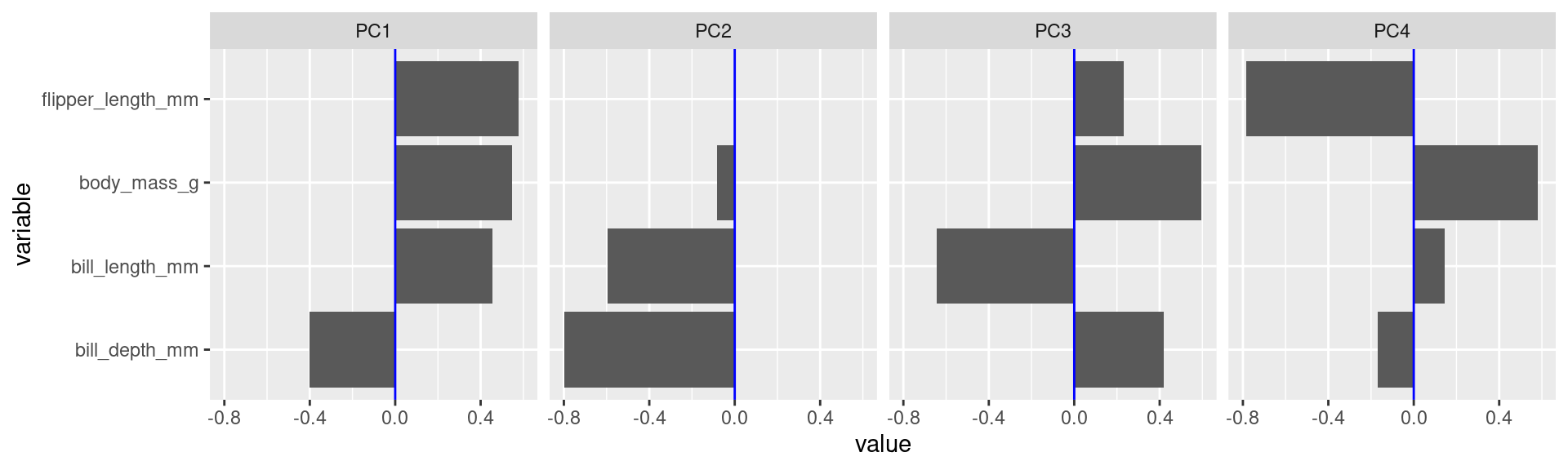
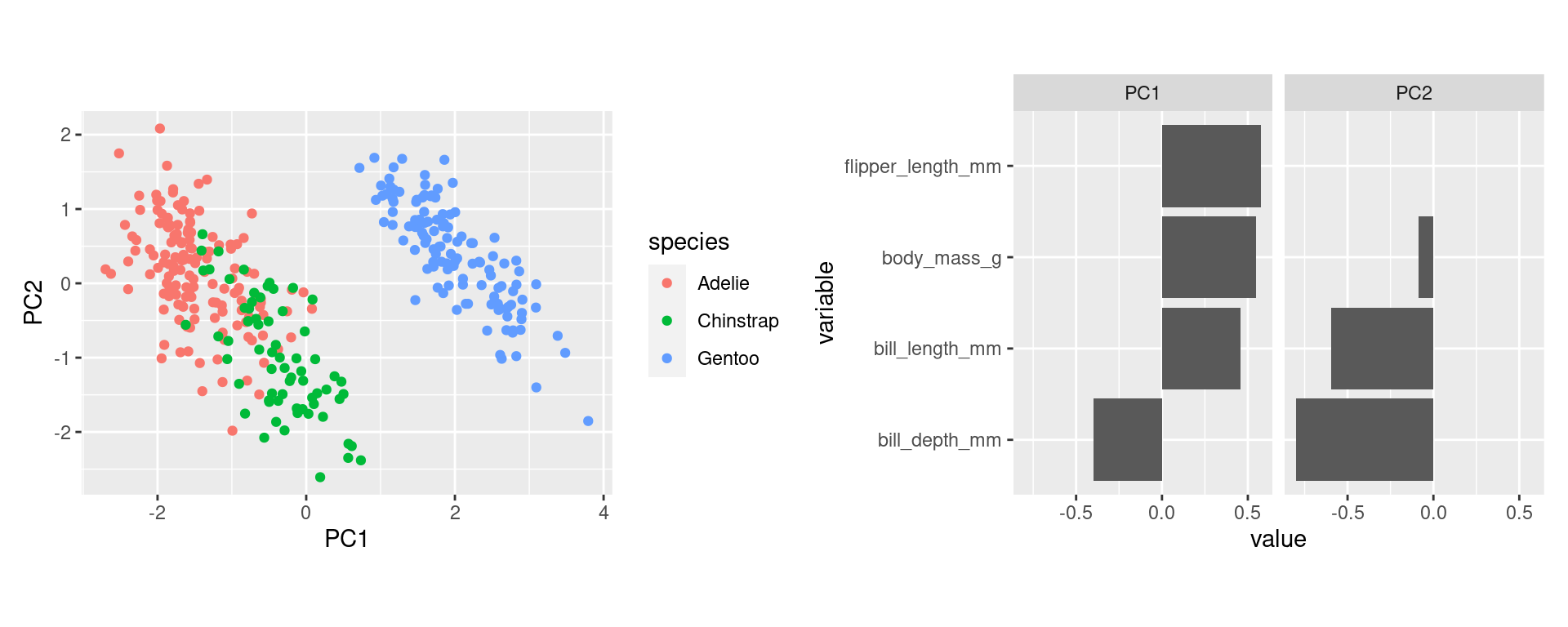
- To score high on PC1 a penguin needs to be generally large but with low bill depth.
- Penguins scoring high on PC2 are penguins with generally small bills.
Interpretations (3)
Relations of PCA
- A technique similar in spirit is factor analysis (e.g.
factanal). It is more theory based as it requires to specify to the theoriezed number of factors up front. - PCA is an example of the importance of linear algebra (“matrixology”) in data science techniques.
- PCA is based on the eigenvalue decomposition of the covariance matrix (or correlation matrix in the standardized case) of the data.
