[1] "EWR" "LGA" "JFK"W#04: Math refresh, Function Programming, Descriptive Statistics
Functions mathematically
Consider two sets: The domain \(X\) and the codomain \(Y\).
A function \(f\) assigns each element of \(X\) to exactly one element of \(Y\).
We write \(f : X \to Y\)
“\(f\) maps from \(X\) to \(Y\)”
and \(x \mapsto f(x)\)
“\(x\) maps to \(f(x)\)”
The yellow set is called the image of \(f\).

Is this a mathematical function?
 \(\ \mapsto\ \)
\(\ \mapsto\ \) 
Input from \(X = \{\text{A picture where a face can be recognized}\}\).
Function: Upload input at https://funny.pho.to/lion/ and download output.
Output from \(Y = \{\text{Set of pictures with a specific format.}\}\)
Yes, it is a function. Important: Output is the same for the same input!
Is this a mathematical function?
Input a text snippet. Function: Enter text at https://www.craiyon.com. Output a picture.

Other examples:
- “Nuclear explosion broccoli”
- “The Eye of Sauron reading a newspaper”
- “The legendary attack of Hamster Godzilla wearing a tiny Sombrero”
![]()


No, it is not a function. It has nine outcomes and these change when run again.
Graphs of functions
- A function is characterized by the set all possible pairs \((x,f(x))\).
- This is called its graph.
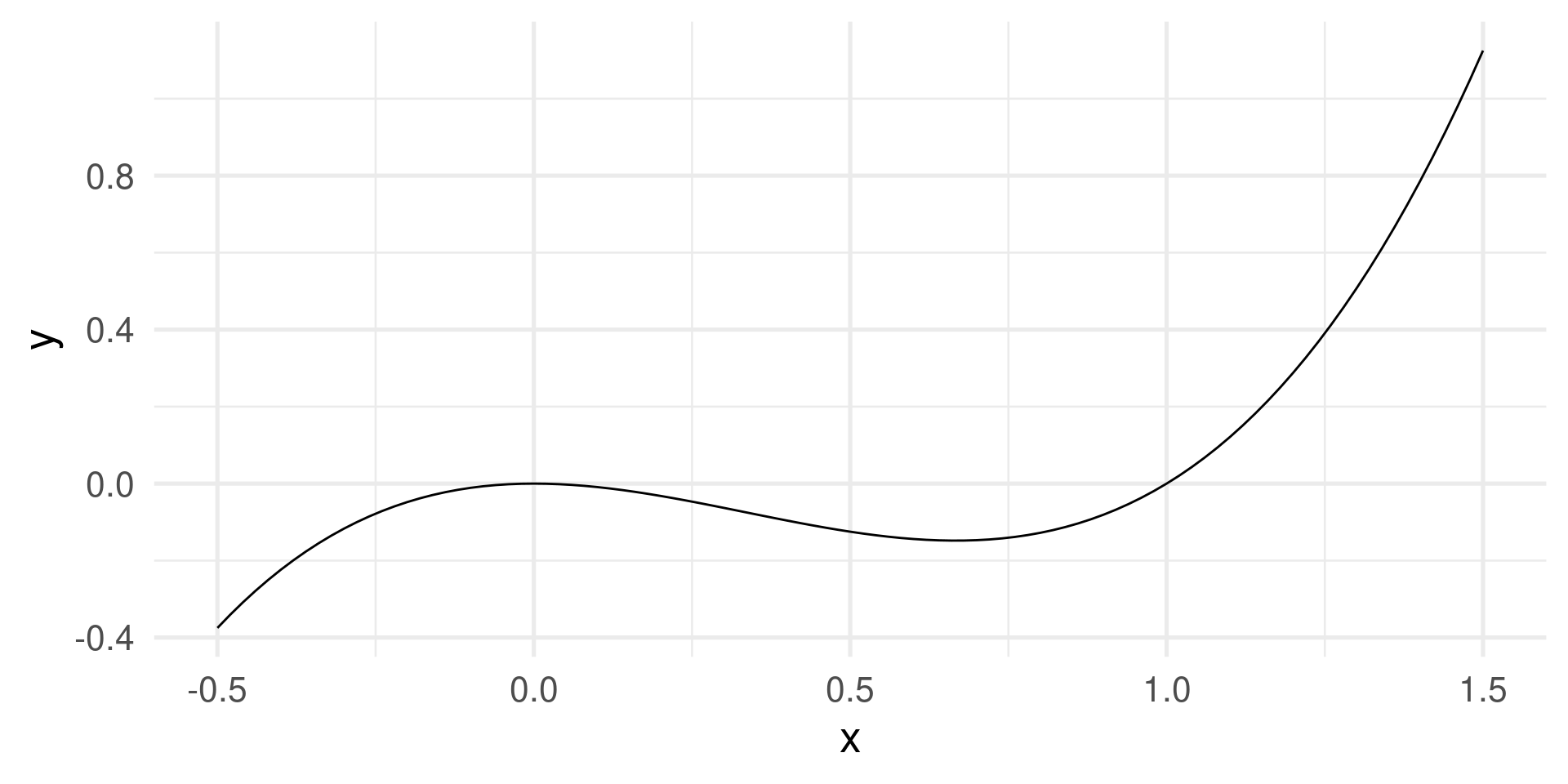
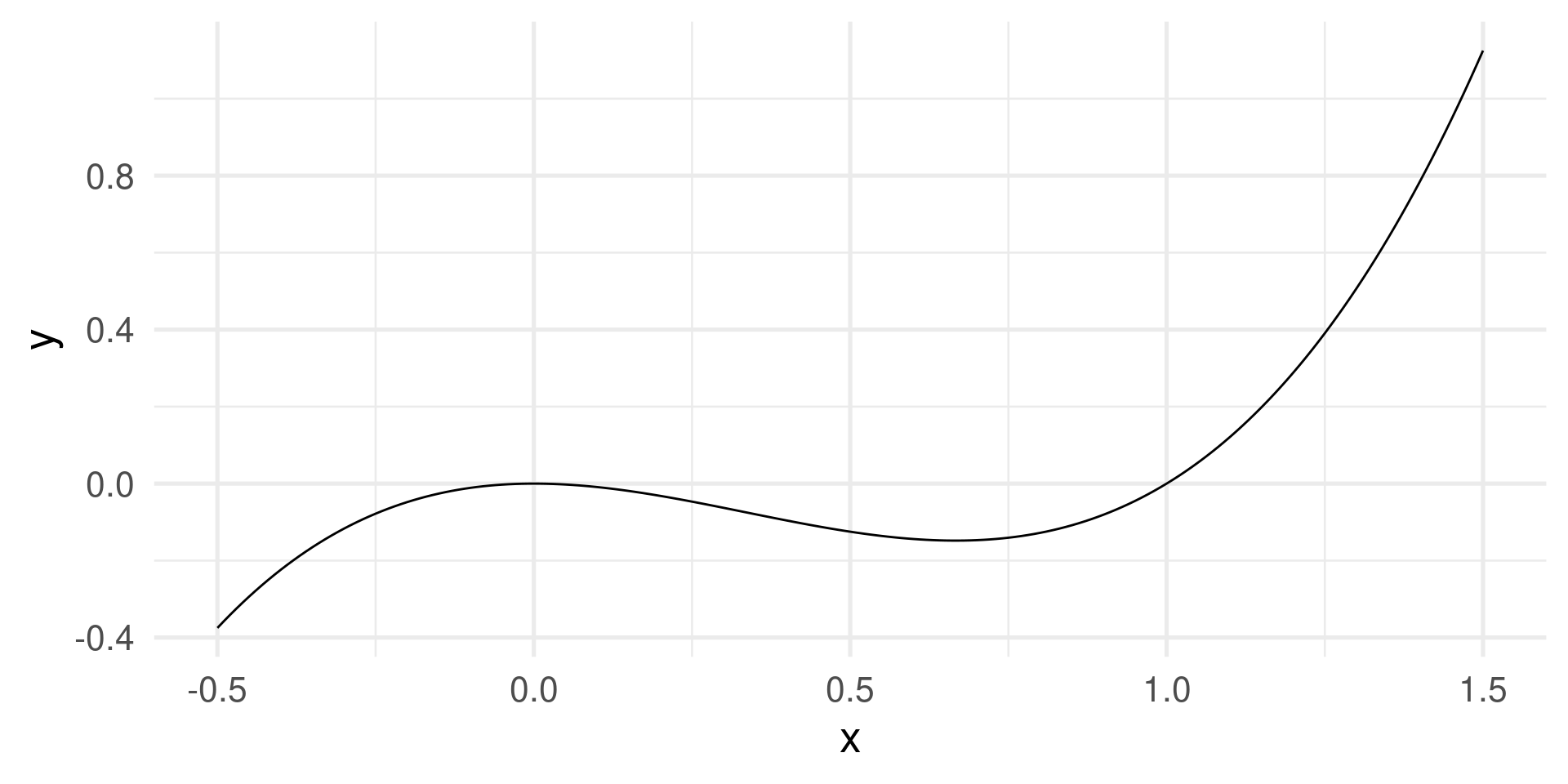
- When domain and codomain are real numbers then the graph can be shown in a Cartesian coordinate system. Example \(f(x) = x^3 - x^2\)
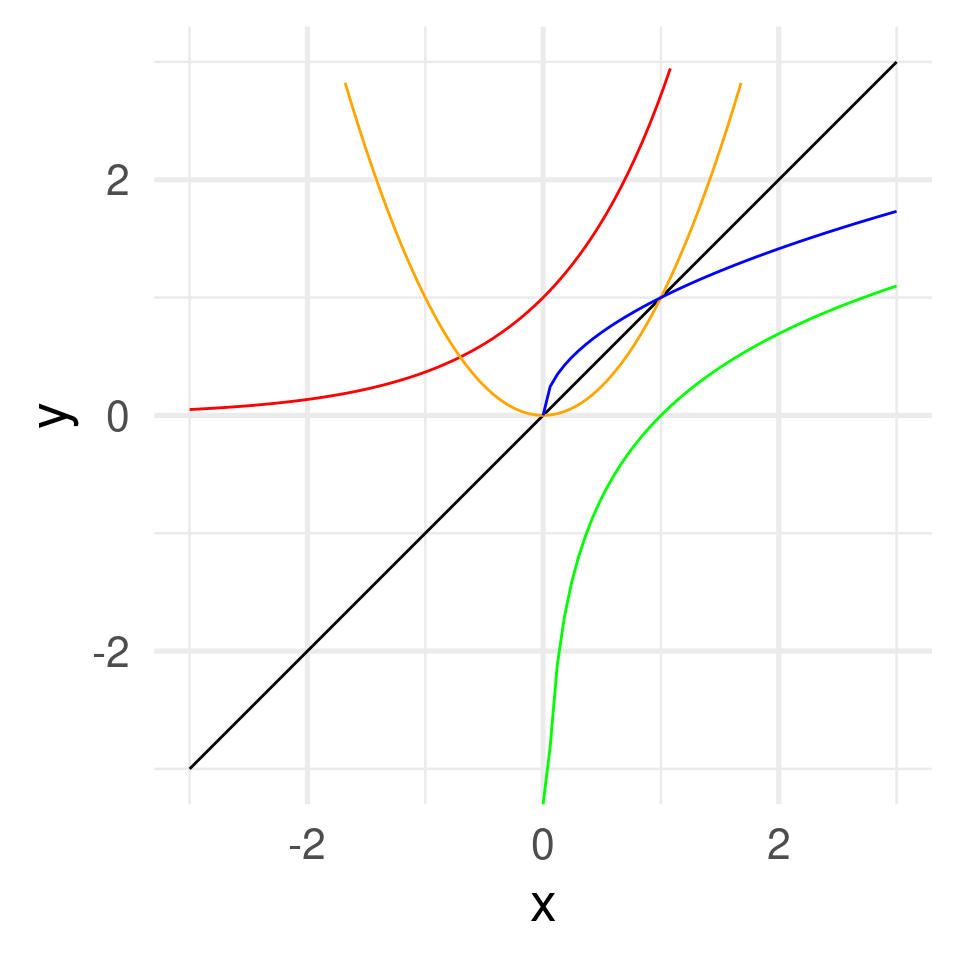
Some functions \(f: \mathbb{R} \to \mathbb{R}\)
\(f(x) = x\) identity function
\(f(x) = x^2\) square function
\(f(x) = \sqrt{x}\) square root function
\(f(x) = e^x\) exponential function
\(f(x) = \log(x)\) natural logarithm
- Square and square root function are inverse of each other. Exponential and natural logarithm, too.
\(\sqrt[2]{x}^2 = \sqrt[2]{x^2} = x\), \(\log(e^x) = e^{\log(x)} = x\)
- Identity function graph as mirror axis.
Shifts and scales
How can we shift, stretch, or shrink a graph vertically and horizontally?
Add a constant to the function.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = x^3 - x^2 + a\)
For \(a =\) -2, -0.5, 0.5, 2
Subtract a constant from all \(x\) within the function definition.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = (x - a)^3 - (x - a)^2\)
For \(a =\) -2, -0.5, 0.5, 2
Attention:
Shifting \(a\) units to the right needs subtracting \(a\)!
You can think of the coordinate system being shifted in direction \(a\) while the graph stays.
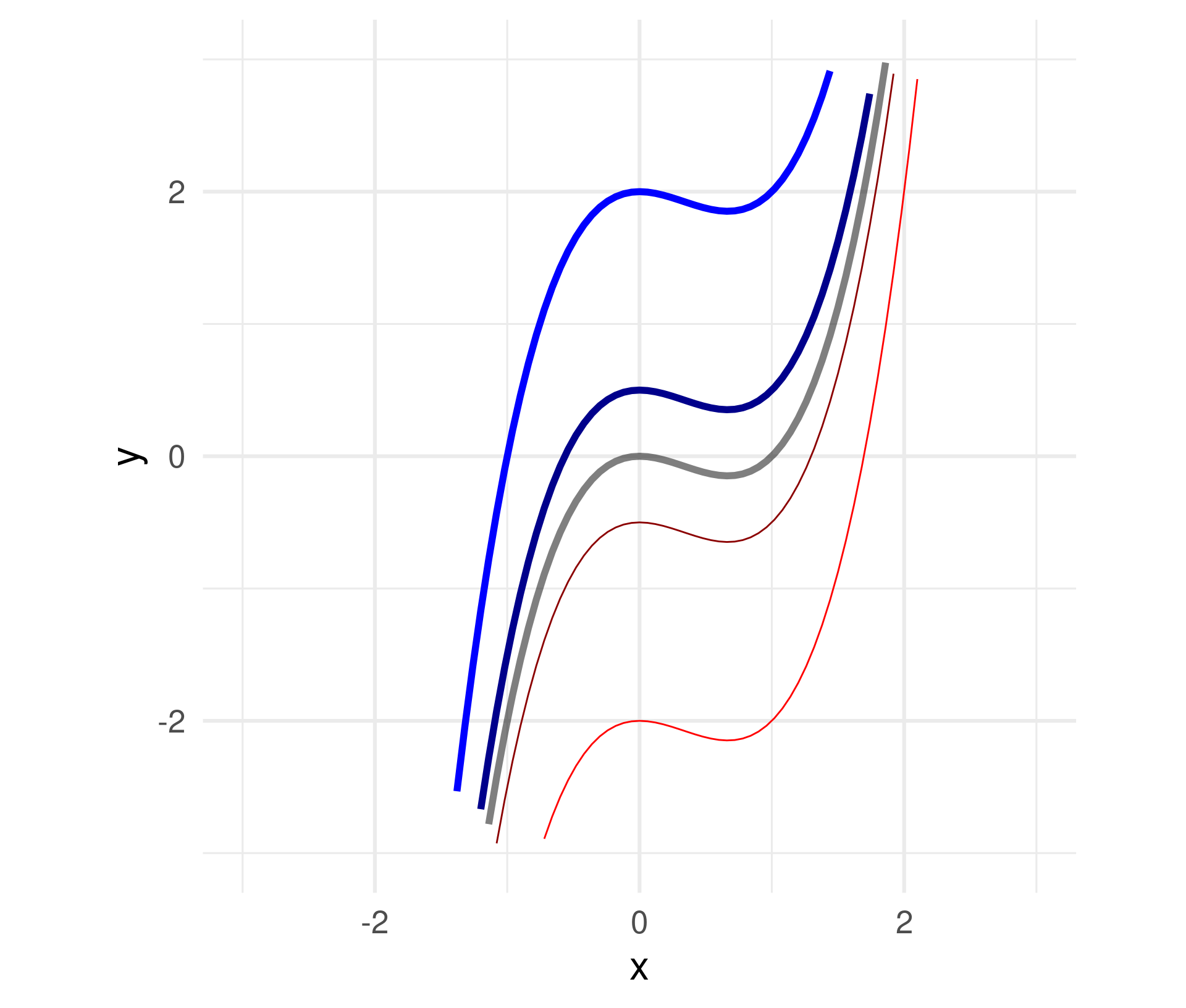
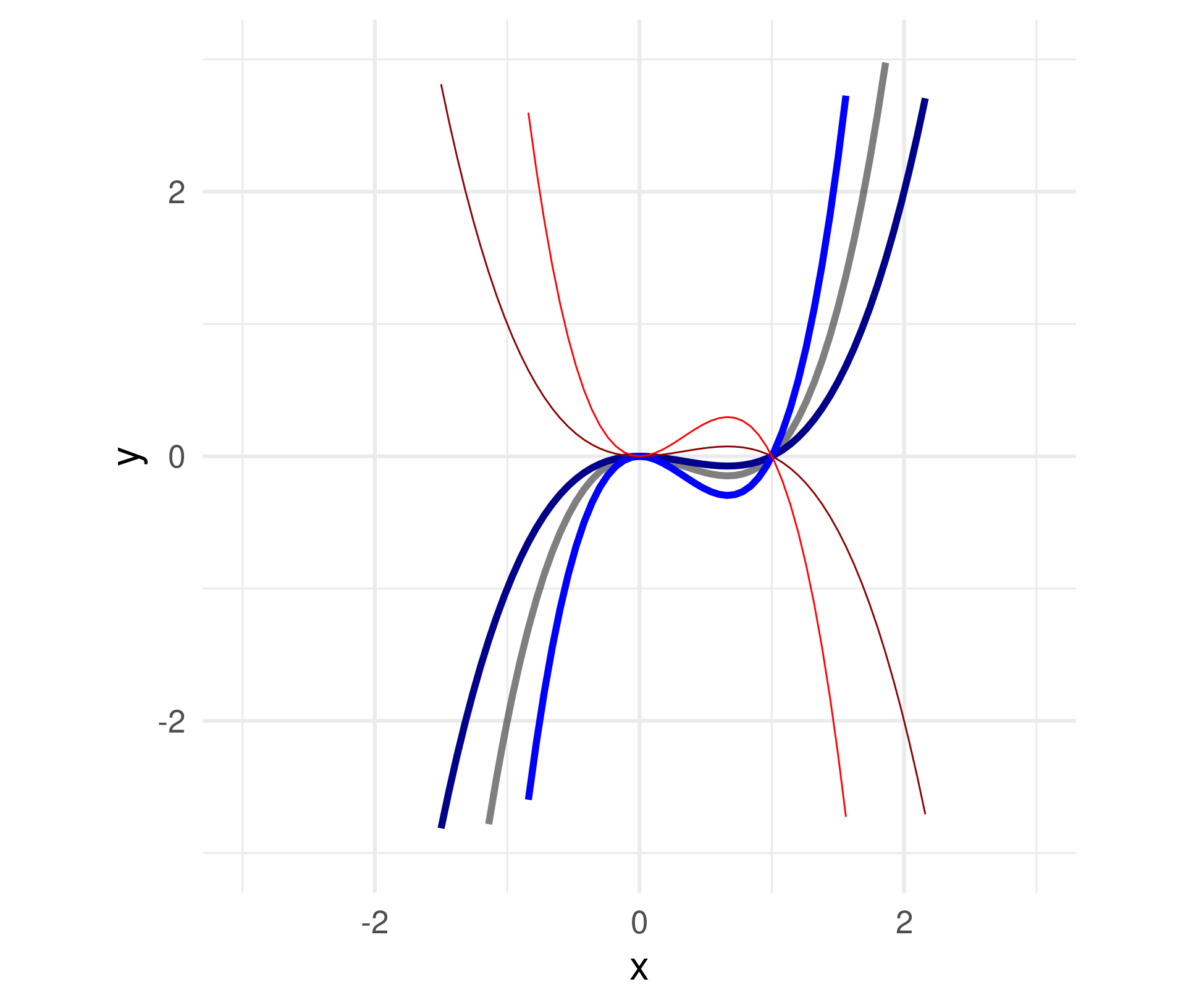
Multiply a constant to all \(x\) within the function definition.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = a(x^3 - x^2)\)
For \(a =\) -2, -0.5, 0.5, 2
Negative numbers flip the graph around the \(x\)-axis.
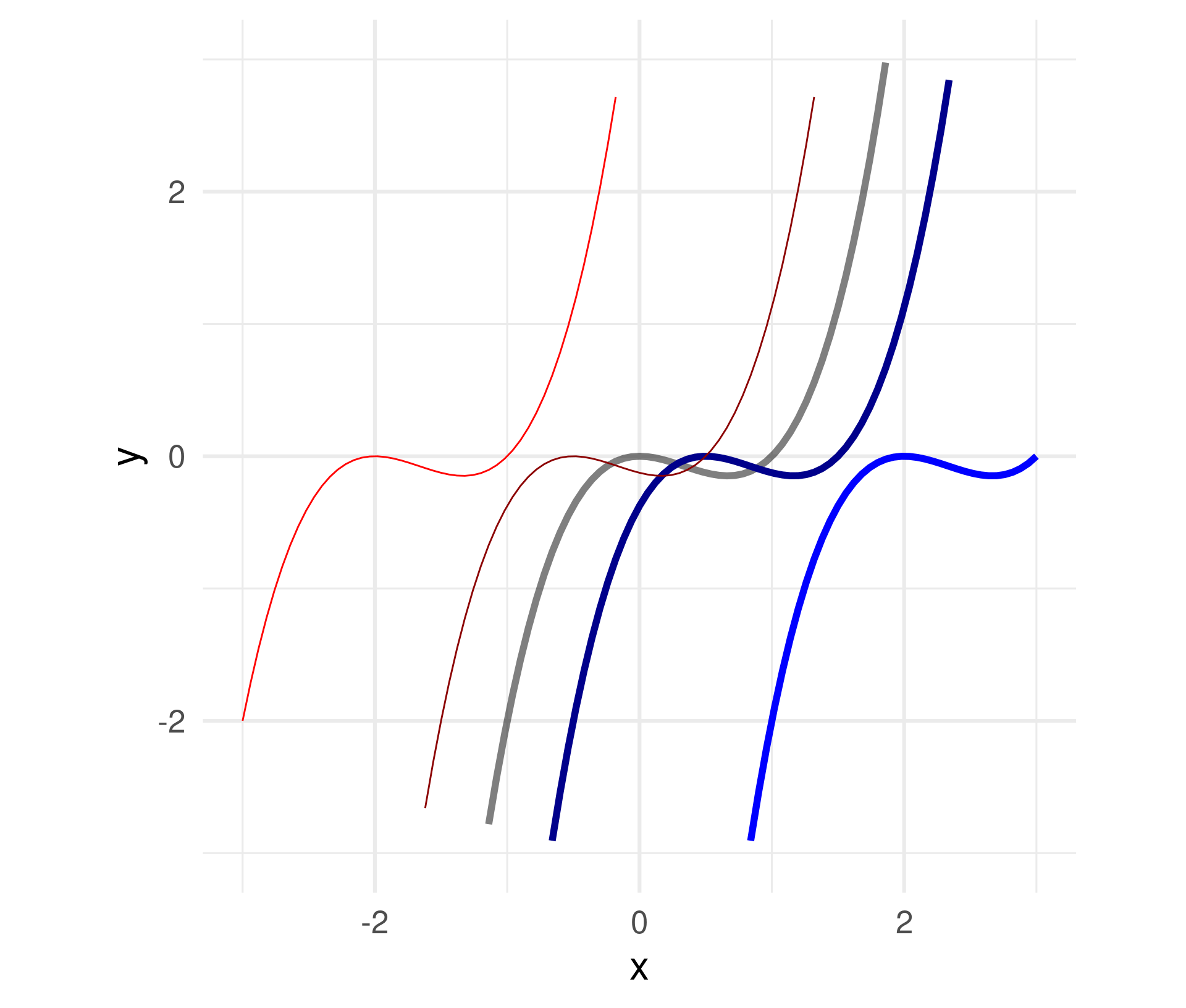
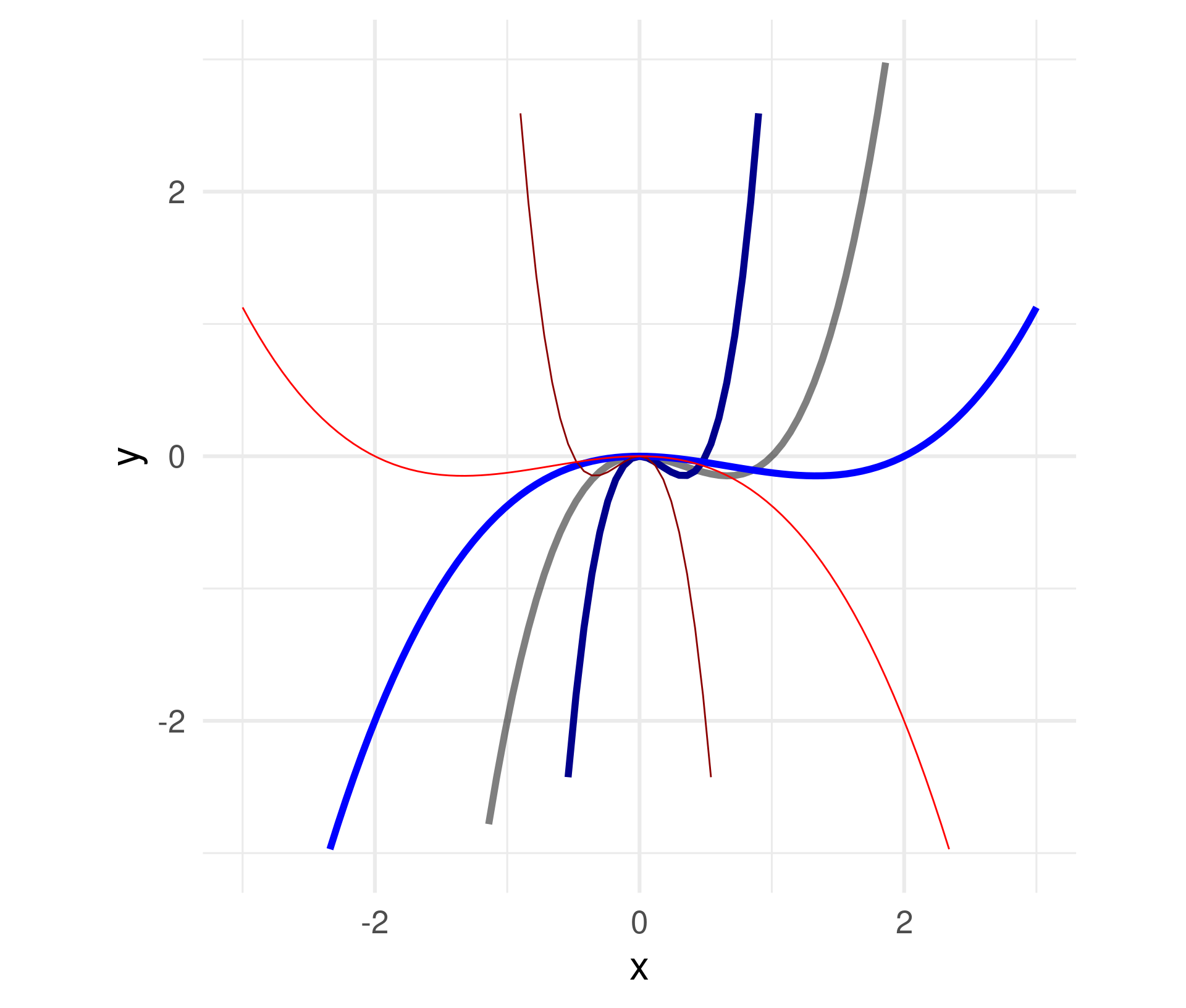
Divide all \(x\) within the function definition by a constant.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = (x/a)^3 - (x/a)^2\)
For \(a =\) -2, -0.5, 0.5, 2
Negative numbers flip the graph around the \(y\)-axis.
Attention: Stretching needs a division by \(a\)!
You can think of the coordinate system being stretched multiplicatively by \(a\) while the graph stays.
Math: Polynomials and exponentials
A polynomial is a function which is composed of (many) addends of the form \(ax^n\) for different values of \(a\) and \(n\).
In an exponential the \(x\) appears in the exponent.
\(f(x) = x^3\) vs. \(f(x) = e^x\)
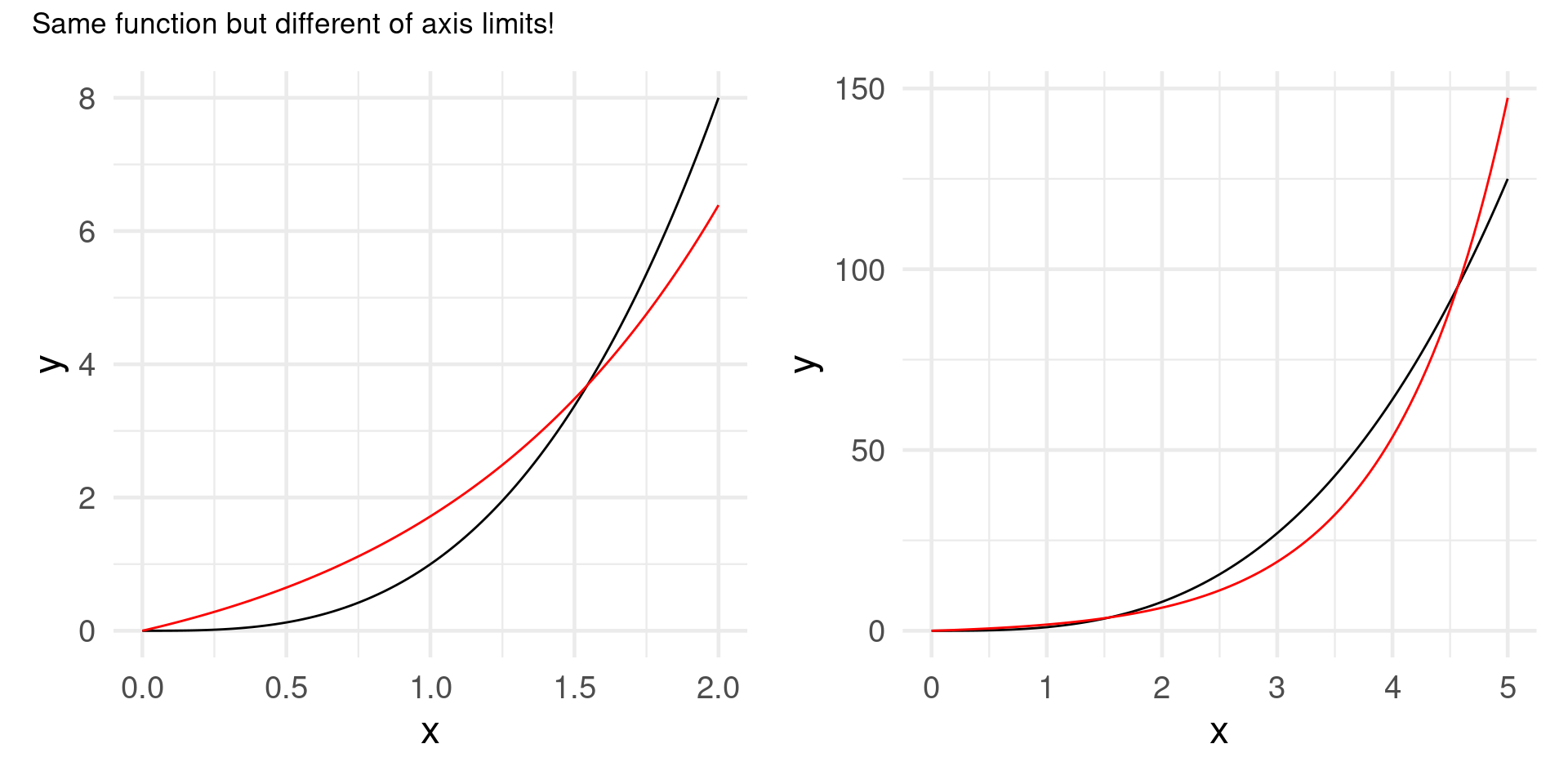
For \(x\to\infty\), any exponential will finally “overtake” any polynomial.
More rules for exponentiation
\(x^a\cdot x^b\)
\(x^a\cdot x^b = x^{a+b}\) Multiplication of powers (with same base \(x\)) becomes addition of exponents.
\((x+y)^a\)
No “simple” form! For \(a\) integer use binomial expansion. \((x+y)^2 = x^2 + 2xy + y^2\)
\((x+y)^3 = x^3 + 3x^2y + 3xy^2 + y^3\)
\((x+y)^n = \sum_{k=0}^n {n \choose k} x^{n-k}y^k\)
Pascal’s triangle

We meet it again in Probability:
A row represents a binomial distribution
Which tends to mimics the normal distribution more and more
and is related to the central limit theorem
Input \(\to\) output

- Metaphorically, a function is a machine or a blackbox that for each input yields an output.
- The inputs of a function are also called arguments.
Difference to math terminolgy:
The output need not be the same for the same input.
Plotting and transformation
Vector creation and vectorized functions are key for plotting and transformation.
Conveniently ggploting functions
Vectorized operations with map
mapfunctions apply a function to each element of a vector.1map(.x, .f, ...)applies the function.fto each element of the vector of.xand returns a list.map_dblreturns a double vector (other variants exist)
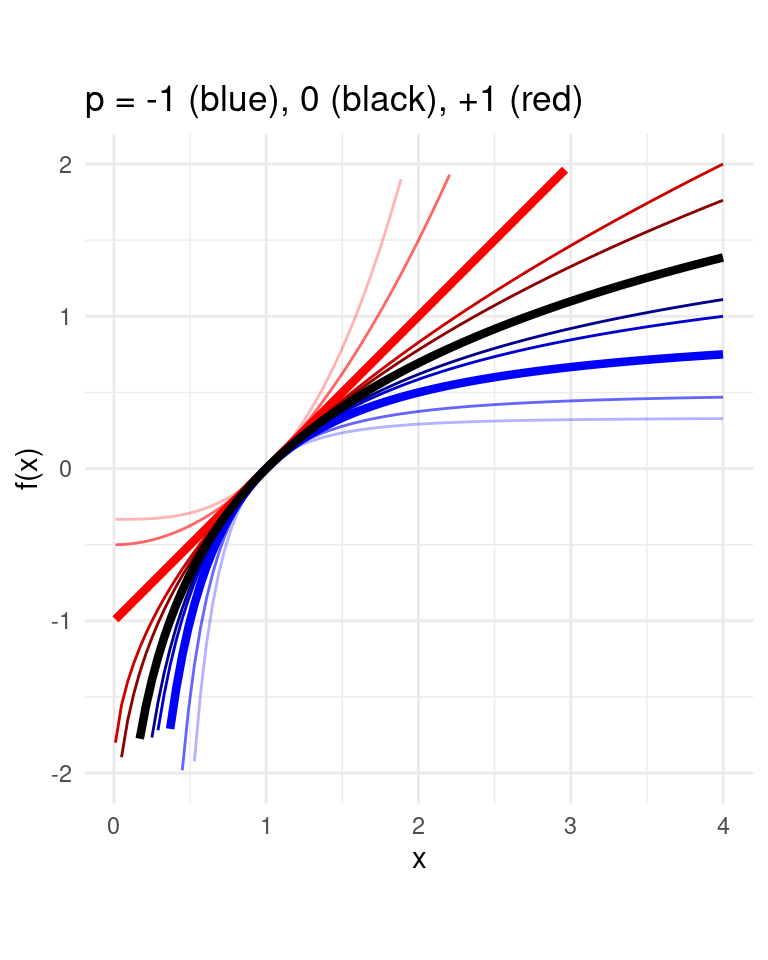
Box-Cox transformation function1
For \(p \in \mathbb{R}\): \(f(x) = \begin{cases}\frac{x^p - 1}{p} & \text{for $p\neq 0$} \\ \log(x) & \text{for $p= 0$}\end{cases}\)
The \(p\)-mean is
\[M_p(x) = f^{-1}(\frac{1}{n}\sum_{i=1}^n f(x_i))\]
with \(x = [x_1, \dots, x_n]\). \(f^{-1}\) is the inverse2 of \(f\).
Application: The Wisdom of the Crowd
- The collective opinion of a diverse group of independent individuals rather than that of a single expert.
- The classical wisdom-of-the-crowds finding is about point estimation of a continuous quantity.
- Popularized by James Surowiecki (2004).
- The opening anecdote is about Francis Galton’s1 surprise in 1907 that the crowd at a county fair accurately guessed the weight of an ox’s meat when their individual guesses were averaged.


Galton’s data1
What is the weight of the meat of this ox?
library(readxl)
galton <- read_excel("data/galton_data.xlsx")
galton |> ggplot(aes(Estimate)) + geom_histogram(binwidth = 5) + geom_vline(xintercept = 1198, color = "green") +
geom_vline(xintercept = mean(galton$Estimate), color = "red") + geom_vline(xintercept = median(galton$Estimate), color = "blue") + geom_vline(xintercept = Mode(galton$Estimate), color = "purple")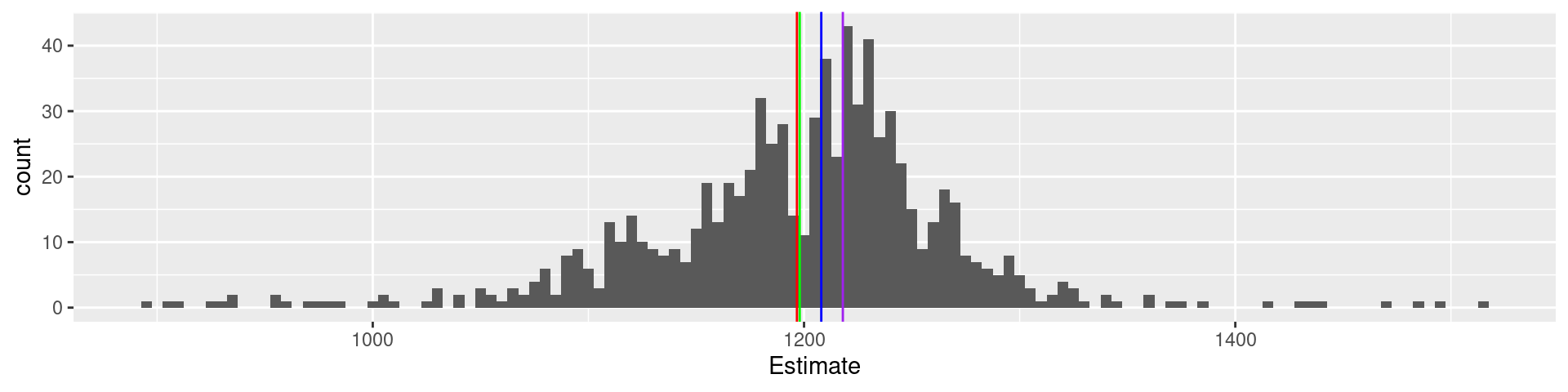
787 estimates, true value 1198, mean 1196.7, median 1208, mode 1218
Viertelfest Bremen 20081
How many lots will be sold by the end of the festival?
viertel <- read_csv("data/Viertelfest.csv")
viertel |> ggplot(aes(`Schätzung`)) + geom_histogram() + geom_vline(xintercept = 10788, color = "green") +
geom_vline(xintercept = mean(viertel$Schätzung), color = "red") + geom_vline(xintercept = median(viertel$Schätzung), color = "blue") + geom_vline(xintercept = Mode(viertel$Schätzung), color = "purple")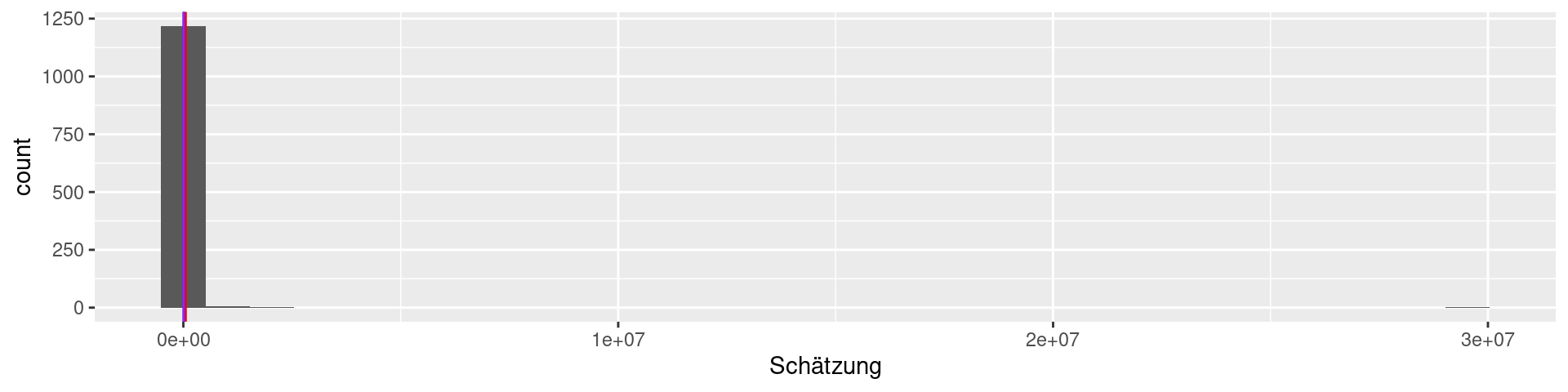
1226 estimates, the maximal value is 29530000!
We should filter out the highest values for the histogram…
Viertelfest Bremen 2008
How many lots will be sold by the end of the festival?
viertel <- read_csv("data/Viertelfest.csv")
viertel |> filter(Schätzung<100000) |> ggplot(aes(`Schätzung`)) + geom_histogram(binwidth = 500) + geom_vline(xintercept = 10788, color = "green") +
geom_vline(xintercept = mean(viertel$Schätzung), color = "red") + geom_vline(xintercept = median(viertel$Schätzung), color = "blue") + geom_vline(xintercept = Mode(viertel$Schätzung), color = "purple") + geom_vline(xintercept = exp(mean(log(viertel$Schätzung))), color = "orange")
1226 estimates, true value 10788, mean 53163.9, median 9843, mode 10000,
geometric mean 10510.1
\(\log_{10}\) transformation Viertelfest
viertel |> mutate(log10Est = log10(Schätzung)) |> ggplot(aes(log10Est)) + geom_histogram(binwidth = 0.05) + geom_vline(xintercept = log10(10788), color = "green") +
geom_vline(xintercept = log10(mean(viertel$Schätzung)), color = "red") + geom_vline(xintercept = log10(median(viertel$Schätzung)), color = "blue") + geom_vline(xintercept = log10(Mode(viertel$Schätzung)), color = "purple") + geom_vline(xintercept = mean(log10(viertel$Schätzung)), color = "orange")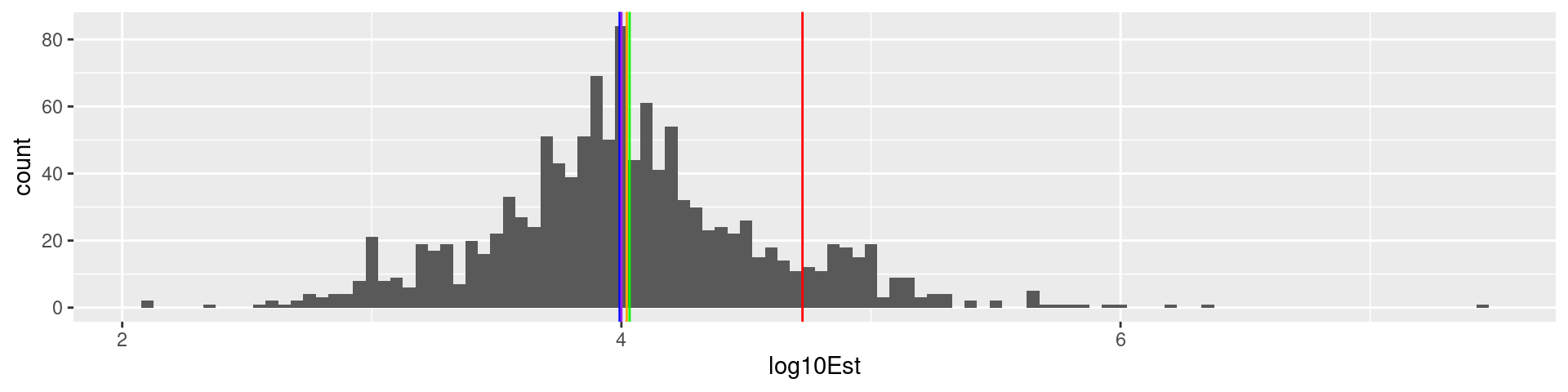
1226 estimates, true value 10788, mean 53163.9, median 9843, mode 10000,
geometric mean 10510.1
Achievements and next steps
- We have learned about the data science process
- You made essential steps in data visualization and data wrangling with New York City Flights in the Homework
- You can write and render reproducible reports
- We had some math refreshment
- We learned some data science data and programming concepts in R and in Python. Reconsider them in later homework!
Next steps coming (you will receive individual repositories for this):
- Homework mimicking data science projects
- Some exploratory data analysis in a sandbox
- Thinking about your own data science project (in groups of 2-3)
